Decision Tree Vs Random Forest: Comparison & Which One To Choose

Is your business struggling to choose the most suitable machine learning model? Deciding between a decision tree vs random forest can directly impact prediction accuracy, operational efficiency, and data-driven decision-making. In this article, MOR Software provides a comprehensive overview and detailed comparison of these two models, helping businesses make informed choices for their projects.
What Is A Decision Tree?
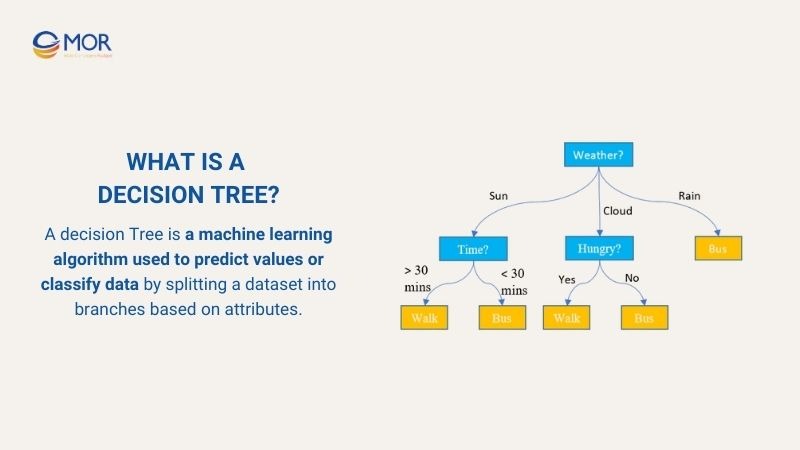
A decision Tree is a machine learning algorithm used to predict values or classify data by splitting a dataset into branches based on attributes. Each node in the tree represents a condition or decision, and each branch leads to a result or another node until reaching a leaf node containing the predicted value.
A Decision Tree is often compared with a Random Forest, especially in discussions about accuracy and interpretability, such as in a decision tree vs random forest scenario.
For example: Consider deciding on a mode of transportation based on weather, time, and hunger:
- Root Node: Weather? This is the first condition checked by the tree. There are three branches:
- Sun → check Time?
- Cloud → check Hungry?
- Rain → directly predict Bus
- Child Node 1: Time? (if sunny)
- If Time > 30 mins → Walk
- If Time ≤ 30 mins → Bus
- Child Node 2: Hungry? (if cloudy)
- If Yes → Walk
- If No → Bus
- Leaf Nodes: The final predicted outcomes (Walk or Bus) are determined by the previous conditions.
How Does A Decision Tree Work?
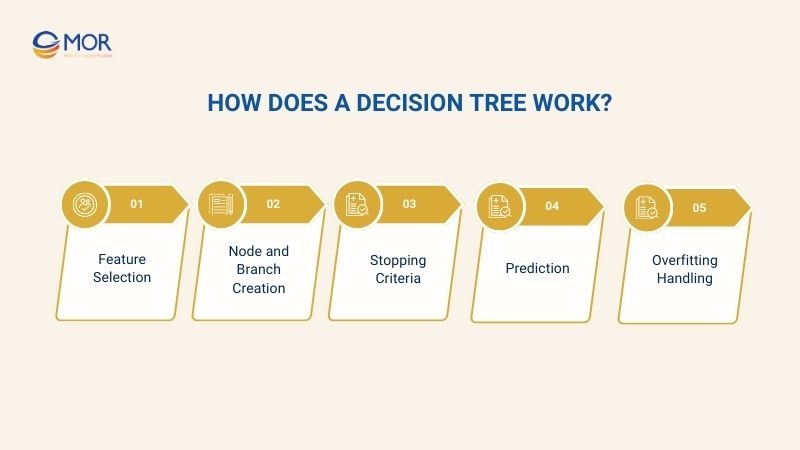
A Decision Tree is a machine learning algorithm used to classify or predict data based on conditions at each node. Here is how a Decision Tree works in detail:
- Feature Selection: The algorithm evaluates all features and selects the best node based on Information Gain, Gini Index, or other criteria.
- Node and Branch Creation: Each node represents a condition to split the data, and each branch leads to a child node or leaf node, which contains the predicted outcome.
- Stopping Criteria: The Decision Tree continues splitting until all data in a node belong to the same class, the maximum depth is reached, or the number of samples in a node is below a minimum threshold.
- Prediction: New samples traverse the Decision Tree following conditions at each node until they reach a leaf node, where the final result is determined.
- Overfitting Handling: A single Decision Tree can be prone to overfitting on complex datasets. Techniques like pruning or limiting depth can reduce overfitting and improve performance.
What Is Random Forest?
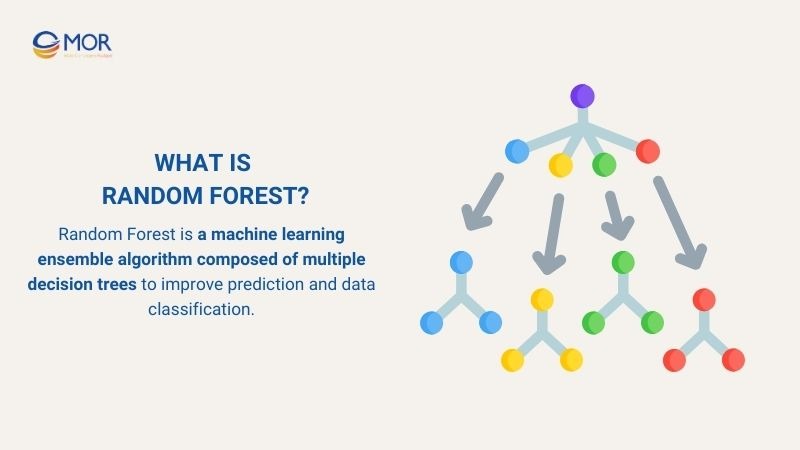
Random Forest is a machine learning ensemble algorithm composed of multiple decision trees to improve prediction and data classification. Each decision tree in the random forest is trained on a random subset of the data and features, helping to reduce overfitting and increase stability.
When making predictions, the Random Forest aggregates results from all decision trees, usually using a voting method to determine the outcome, achieving higher accuracy compared to a single Decision Tree.
How Does Random Forest Work?
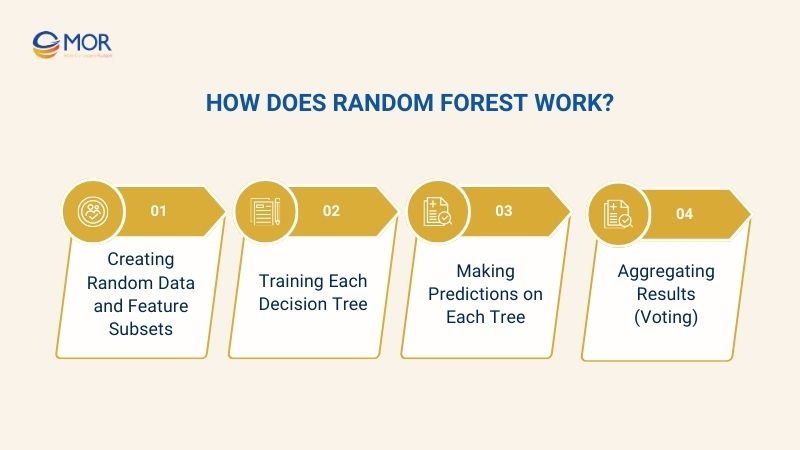
Random Forest is a collection of multiple decision trees, each trained on a random subset of data and features. The detailed working process is as follows:
- Creating Random Data and Feature Subsets: The algorithm randomly selects a subset of data and a subset of features for each decision tree.
- Training Each Decision Tree: Each decision tree is built independently, using conditions at each node to classify or predict data.
- Making Predictions on Each Tree: When a new sample is input, each decision tree in the random forest provides its prediction.
- Aggregating Results (Voting): The final output of the Random Forest is determined by voting or averaging predictions from all decision trees.
Key Difference Between Decision Tree Vs Random Forest
When choosing between a decision tree vs random forest, it is crucial to understand their key differences to select the most suitable model for your data. Understanding these distinctions helps data scientists and analysts make informed decisions when building predictive models.
Aspect | Decision Tree | Random Forest |
Data Processing | Handles data directly with minimal preprocessing. Works well with small or clean datasets. | Uses multiple random subsets of data and features for each decision tree, making it suitable for large, complex datasets with diverse features. |
Complexity | Low complexity, easy to understand, implement, and visualize. | Higher complexity due to the ensemble of multiple decision trees, making the model structure less transparent. |
Overfitting | Prone to overfitting, especially on small datasets with noisy data. | Reduces overfitting by aggregating predictions from multiple decision trees, improving generalization. |
Training Time | Fast to train, ideal for small datasets or quick experiments. | Slower to train because it builds many decision trees, requiring more computational resources. |
Stability to Change | Sensitive to small changes or noise in the dataset, which can affect predictions. | More stable, predictions remain consistent even when the data changes slightly, thanks to ensemble voting. |
Performance | Performs well on simple or medium-sized datasets but may struggle with complex patterns. | Provides higher accuracy and better performance on large, high-dimensional datasets. |
Interpretability | Easy to visualize as a single tree, making it straightforward to explain decisions to stakeholders. | Harder to interpret individual predictions, but feature importance can be analyzed across all decision trees. |
Predictive Time | Fast for predicting new samples because only a single tree is traversed. | Slower because predictions are aggregated from multiple decision trees, though still practical for most applications. |
Handling Outliers | Sensitive to outliers, which can skew splits and predictions. | More stable in the presence of outliers, as ensemble voting mitigates the impact of extreme values. |
Feature Importance | Can be inferred directly from the splits of the single tree. | Provides overall feature importance across all decision trees, offering deeper insight into influential features. |
Implementing Decision Tree Vs Random Forest In Python
In Python, implementing Decision Tree and Random Forest allows you to visualize and compare the performance of the decision tree vs random forest on real datasets. Below are the detailed steps to implement them
Step 1: Loading the Libraries and Dataset
To start implementing decision tree vs random forest, you first need to load the essential Python libraries. Commonly used libraries include:
- pandas: for handling tabular data, reading, and manipulating datasets.
- numpy: for numerical operations and matrix calculations on the data.
- scikit-learn: provides tools to build and train both decision tree vs random forest, as well as evaluate model performance.
After importing the libraries, select a sample dataset for practice, such as Iris, Titanic, or any dataset suitable for prediction or classification tasks. This step ensures your environment is ready for comparing decision tree vs random forest performance.
Step 2: Data Preprocessing
Proper data preprocessing is crucial for enhancing the accuracy and performance of decision tree vs random forest models. It ensures the models can learn efficiently and make stable predictions.
Key preprocessing tasks include:
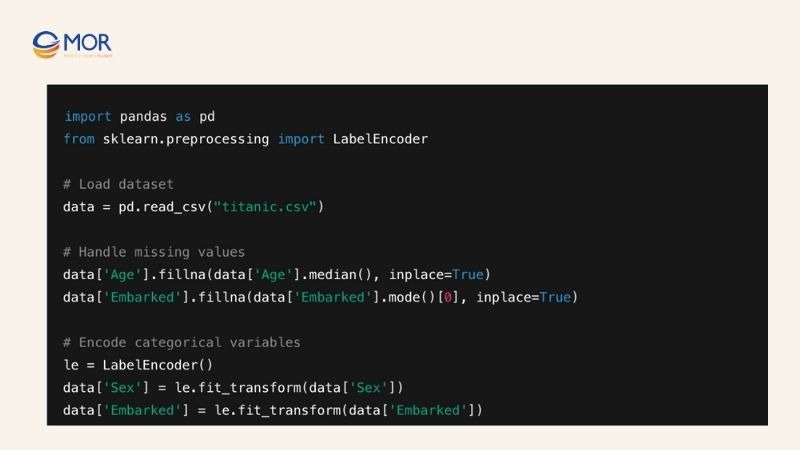
- Handling missing values: Fill or remove missing data to prevent errors during training.
- Encoding categorical variables: Convert non-numeric data into numbers for the models to understand.
- Scaling features if necessary: While decision tree vs random forest are not sensitive to feature scaling, normalization can help compare performance across different models.
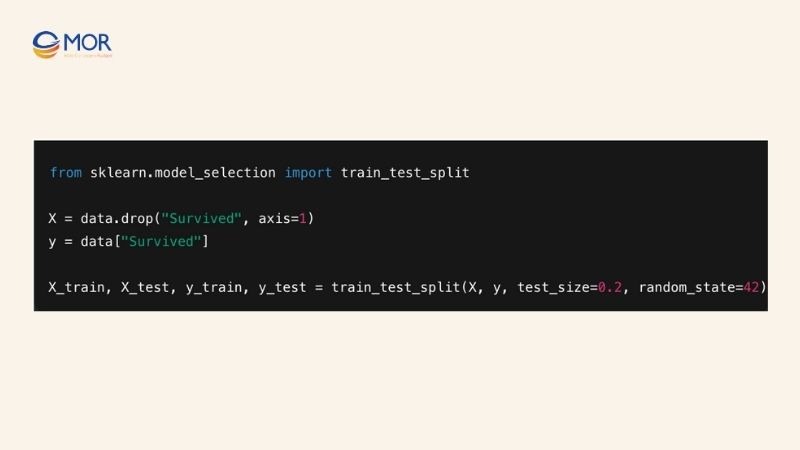
Step 3: Creating Train and Test Sets
To properly evaluate the decision tree vs random forest, split the dataset into training and testing sets. This allows each model to learn from the training data and be validated on unseen test data, measuring real predictive performance.
- Train set: Used to train decision tree vs random forest, helping the models learn the decision nodes and branches.
- Test set: Used to assess accuracy and stability. It highlights if the model overfits the training data.
Example code:
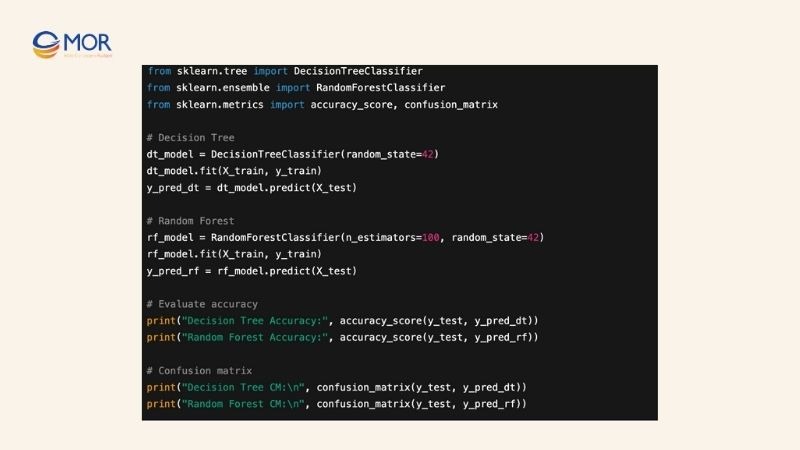
Step 4: Building and Evaluating the Model
After preprocessing and splitting the data, you can build and train both decision tree vs random forest models, then evaluate their performance.
- Build models: Each model learns from the training data to determine the best splits at each node.
- Predict on test set: Both models generate predictions, allowing direct comparison.
- Evaluate results: Utilize accuracy, a confusion matrix, and other metrics to assess predictive performance.

When To Use Decision Tree vs Random Forest?
When choosing between decision tree vs random forest, it is essential to identify the appropriate scenarios for each algorithm. Below are the common situations for each model:
Scenarios for Using Decision Tree
Decision Tree is often the ideal choice in practical scenarios where interpretability, training speed, and small to medium datasets are important:
- Small or medium-sized datasets: When the dataset is not very large, a single decision tree can learn enough patterns without causing excessive overfitting.
- When interpretability is crucial: Decision tree allows you to visualize the decision-making process, from root node to leaf nodes, making it easy for stakeholders to understand how the model predicts.
- Prioritizing computational speed and resources: If fast training and low resource usage are important, decision tree is suitable since it does not require building multiple trees like a random forest.
Scenarios for Using Random Forest
Random Forest is suitable for scenarios that require high accuracy and handling complex datasets:
- Large datasets with many features: When the dataset has many attributes and samples, random forest leverages multiple decision trees to learn effectively and improve performance compared to a single decision tree.
- Minimizing overfitting and maximizing accuracy: Random forest combines predictions from multiple decision trees, providing more stability and reducing the risk of overfitting. For instance, in colorectal cancer classification, Random Forest achieved 91.65% compared to 87.22% for Decision Tree.
- Datasets with noise or outliers: When the dataset contains noise or outliers, random forest maintains stability and delivers more accurate predictions through voting from all trees.

How To Choose Between Decision Tree vs Random Forest?
When choosing between decision tree vs random forest, identifying the right criteria to select a model is crucial. Here are some key factors to consider that can help your business make the optimal decision for the project.
Based on Accuracy Requirements
When choosing between decision tree vs random forest, accuracy is a key factor. If your project requires high accuracy and aims to minimize prediction errors, Random Forest is the preferred choice. By combining multiple decision trees, Random Forest can aggregate results through voting, improving performance and reducing overfitting compared to a single decision tree.
On the other hand, if you need a fast, interpretable model where understanding the decision process is more important than maximum accuracy, a Decision Tree is still a good option. Its clear structure allows you to visualize decisions from the root node to leaf nodes.
Based on the Dataset Size
When selecting between decision tree vs random forest, the size and characteristics of your dataset are crucial. For small datasets, a single decision tree is often sufficient to learn patterns without significant overfitting. It is also fast to train and predict.
For example, with the Iris dataset (150 samples, 4 features), a single decision tree can classify almost all flower types accurately. Using Random Forest on this dataset provides little additional benefit and requires more training time.
Based on Interpretability
One of the main advantages of a decision tree is its interpretability. You can visualize the entire process from the root node to leaf nodes, helping stakeholders understand why the model makes specific predictions.
Conversely, Random Forest consists of multiple decision trees, making it harder to interpret individual decisions. However, you can still evaluate feature importance from Random Forest, identifying the most influential factors on predictions without explaining each tree in detail.
Based on Computational Resources
Random Forest requires more computational resources because it builds and trains multiple decision trees. This can be time-consuming and memory-intensive, especially for large datasets.
In contrast, a single decision tree is lightweight, faster, and suitable for environments with limited computational resources. If your project needs rapid deployment or must run on devices with restricted capacity, a decision tree is the optimal choice.

In Conclusion
Understanding the differences between decision tree vs random forest enables your business to make confident, data-driven decisions. While a decision tree offers simplicity and easy interpretability, a random forest delivers higher accuracy and stability for complex datasets. Contact MOR Software today to have our experts support your data strategy and help drive impactful business outcomes.
MOR SOFTWARE
Frequently Asked Questions (FAQs)
Which is more accurate, a decision tree or a random forest?
Random Forest is more accurate than a Decision Tree because it averages multiple trees, reducing overfitting and variance.
Is a random forest more stable than a decision tree?
Yes, Random Forest is more stable than a Decision Tree because combining multiple trees smooths out individual fluctuations.
Is random forest just a bunch of decision trees?
Yes, Random Forest consists of multiple Decision Trees, but adds randomness in sampling and feature selection to improve predictions.
What is the main purpose of using multiple decision trees in a random forest?
The primary purpose is to reduce overfitting and enhance predictive performance by aggregating the outputs from multiple trees.
What distinguishes the random forest algorithm from a single decision tree?
Random Forest builds many Decision Trees on random subsets of data and features, then aggregates their predictions for higher accuracy.
What is the relationship between decision tree vs random forest?
Random Forest is an ensemble method of Decision Trees that combines their outputs to produce more accurate and stable predictions.
Share





Rate this article
0
over 5.0 based on 0 reviews
Your rating on this news:
Name
*Email
*Write your comment
*Send your comment
1