A Complete Introduction to K Nearest Neighbor Algorithm
Is your business looking to enhance predictive analytics and decision-making? The K Nearest Neighbor algorithm offers a simple yet powerful solution for classification and prediction tasks in machine learning. In this article, MOR Software will explore how to leverage KNN to streamline your business data processes, enabling to extract valuable insights without the need for complex model training.
What Is The K Nearest Neighbor Algorithm?
Before exploring the details of the KNN classifier, it is important to understand what “K” in the K Nearest Neighbor Algorithm means.
What Is “K” in the K Nearest Neighbour Algorithm?
In the K nearest neighbor algorithm, the symbol “K” represents the number of k nearest neighbors (the closest data points) considered when comparing to a new data point.

For example:
If K = 5, the algorithm will look at the 5 closest neighbors to decide the result. A very small K may make the model too sensitive to noise, while a very large K may include distant points that reduce accuracy.
Therefore, choosing the optimal K is crucial for reliable performance.
Definition of the K Nearest Neighbor Algorithm
The k nearest neighbor algorithm is a nearest neighbor algorithm in supervised machine learning. Instead of building a complex training model, the algorithm K-nearest neighbor stores all training data.
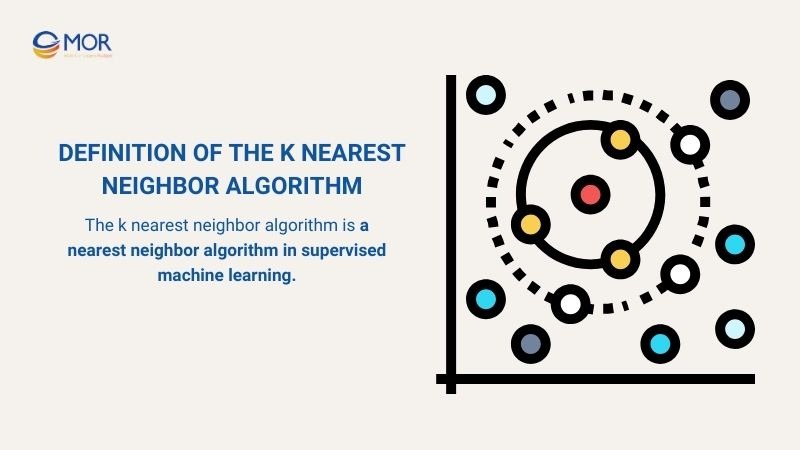
When a new data point arrives, the KNN classifier will:
- Calculate the distance between the new point and all training points.
- Identify the K nearest neighbours.
- Use majority voting for classification or take the average of neighbors for regression.
>>> Discover how to effectively find and select high-quality info sets used in machine learning to power your AI projects. Let’s start!
How Does The K Nearest Neighbor Algorithm Work?
After understanding the definition, the next question is how the k nearest neighbor algorithm works. Below are the basic steps of a nearest neighbors algorithm in machine learning:
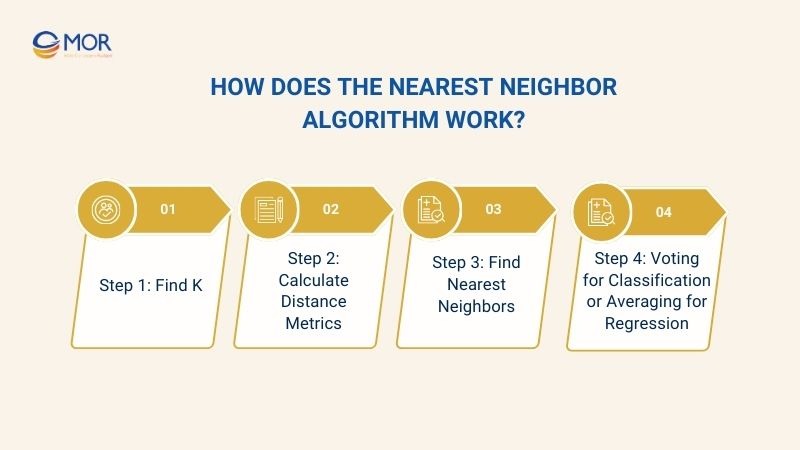
Step 1: Find K
In the k nearest neighbor algorithm, the first step is to determine the K value, which represents the number of nearest neighbors used to compare with a new data point. K directly affects the performance of the KNN classifier:
- A small K can make the model sensitive to noise, as predictions rely on only a few neighbors.
- A large K can dilute the results, including distant points that may not reflect the true pattern of the data.
Optimal K selection is usually done experimentally by testing different values and evaluating performance with a validation set or cross-validation. Choosing the right K balances accuracy and generalization in machine learning.
Step 2: Calculate Distance Metrics
After selecting K, the next step in the K nearest neighbor algorithm is to calculate the distance between the new point and all points in the training data. Common distance metrics include:
- Euclidean distance: the most common linear distance for numeric data.
- Manhattan distance: the sum of absolute differences across dimensions, useful for grid-like or discrete features.
- Minkowski distance: a generalization of Euclidean and Manhattan distances, with a parameter p to adjust flexibility.
Choosing the right distance metric directly impacts the accuracy of K nearest neighbors machine learning, especially for datasets with diverse features.
Step 3: Find Nearest Neighbors
After computing distances, the K nearest neighbor algorithm identifies the K closest neighbors to the new data point. This step ensures that the KNN classifier selects the most relevant neighbors for accurate prediction.
Finding nearest neighbors correctly is crucial for reflecting the underlying data structure. For large datasets, optimization techniques like KD-trees or Ball-trees can speed up the search process.
Step 4: Voting for Classification or Averaging for Regression
Finally, the k nearest neighbor algorithm predicts outcomes based on the selected nearest neighbors:
- Classification: applies a majority vote, where the most frequent class among the K nearest neighbors is assigned to the new point.
- Regression: calculates the average value of the neighbors to predict a continuous outcome.
This simple yet effective approach allows k nearest neighbors machine learning to perform well in both classification and regression tasks while maintaining ease of implementation.
Popular Calculations In The K Nearest Neighbor Algorithm
After understanding how the k-nearest neighbor algorithm works, the next step is to explore the popular calculations in KNN. Among them, two key tasks directly impact the performance of a KNN classifier:

Choosing K
In the k nearest neighbor algorithm, selecting the optimal K directly impacts the performance of the KNN classifier and the model’s generalization ability. Common methods to choose K include:
- Cross-validation: Split the dataset into multiple folds, test different K values, calculate the average accuracy across folds, and select the K with the best performance.
- Validation set: Set aside a portion of the data as a validation set, try different K values, and choose the K that achieves the highest accuracy.
- Elbow method: plot the prediction error rate against K, and select the K at the “elbow point” where the error reduction starts to slow down.
- Weighted KNN: assign weights to neighbors based on distance, combined with K selection, to improve prediction accuracy.
- Adaptive K: adjust K for each data point based on local density, making the KNN classifier more flexible with uneven data distributions.
Using the right method ensures the k nearest neighbor algorithm balances between overfitting and underfitting, optimizing prediction accuracy and performance on new datasets.
Calculating Distance Metrics
After selecting K, the next step in the k nearest neighbor algorithm is to calculate distance metrics to determine the proximity between the new data point and training points. This step helps the KNN classifier identify the most relevant neighbors.
Popular distance metrics include:

- Euclidean Distance – the most common linear distance for numerical data:
- Manhattan Distance – the sum of absolute differences across each dimension, useful for grid-like or discrete data:
- Minkowski Distance – a generalization of Euclidean and Manhattan, allowing adjustment with a parameter
Choosing the appropriate distance metric is a critical calculation in the k nearest neighbor algorithm, especially when the dataset contains multiple features with different scales and distributions.
K Nearest Neighbor Algorithm In Python
After understanding the working mechanism and key calculations of the k nearest neighbor algorithm, the next step is to implement this algorithm in Python. Below is a detailed step-by-step guide:
Import Libraries
The first step in implementing the K Nearest Neighbor algorithm in Python is to import the necessary libraries. Typically, we use numpy for numerical operations and scikit-learn for dataset handling or built-in KNN utilities.

Here, numpy is used for calculating Euclidean distance, while train_test_split helps divide the dataset into training and test sets. Using datasets like Iris allows quick experimentation with KNN machine learning without external files.
Define Euclidean Distance Function
In the K Nearest Neighbor algorithm, measuring the distance between a new data point and training points is crucial. Euclidean distance is the most common metric, especially for numerical data.

Explanation:
- point1 and point2 are numpy arrays representing data points.
- (point1 - point2) ** 2 calculates squared differences for each dimension.
- np.sum() sums these squared differences.
- np.sqrt() takes the square root to return the Euclidean distance.
This function is repeatedly used to identify the k nearest neighbours, ensuring the KNN classifier selects the closest points accurately.
KNN Prediction Function
After defining the distance function, we create a prediction function for the K Nearest Neighbors. This function follows four key steps:
- Calculate distances from the test point to all training points.
- Sort distances and select the K nearest points.
- Extract labels of the K nearest neighbors.
- Use majority voting (for classification) or averaging (for regression).
Classification example:

Explanation:
- np.argsort(distances) sorts indices of points by increasing distance.
- [:k] selects the K nearest indices.
- max(set(...), key=...) chooses the label appearing most frequently (majority vote).
This function is the core of KNN machine learning, predicting labels for any new data point.
Training Data, Labels, And Test Point
Before predicting, we need to prepare the training and test data. This step is critical for K Nearest Neighbor Python, as data must be in numpy array format for distance calculations to work correctly:

- X_train is a matrix containing data points.
- y_train contains corresponding labels.
- test_point is the new data point for prediction.
Properly formatted data ensures the KNN algorithm identifies the correct nearest neighbors efficiently.
Make Prediction
Finally, after preparing the data and defining the functions, we call knn_predict to obtain the prediction. This step demonstrates the simplicity and effectiveness of KNN machine learning:
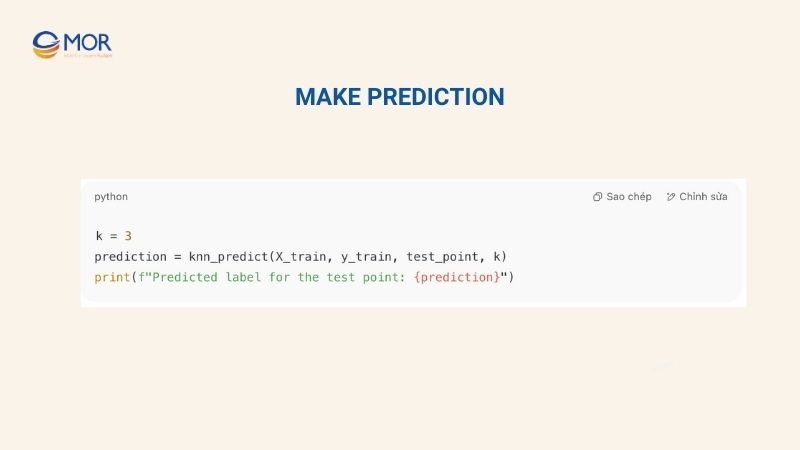
Explanation:
- k = 3 selects 3 nearest neighbors.
- prediction stores the label predicted using majority vote from the 3 closest points.
- print() displays the result, illustrating how the KNN classifier works in practice.
This implementation is straightforward yet effective, making it ideal for understanding the K Nearest Neighbor Algorithm in Python and easily scalable to larger datasets.
Applications Of K Nearest Neighbor In Machine Learning
This algorithm is simple and highly effective across various fields. Each application leverages the KNN classifier’s ability to identify the nearest data points for accurate prediction or classification.
Recommendation Systems
The KNN classifier measures the distance between users or items based on features such as ratings, purchase behavior, or viewing history. When making recommendations, the algorithm selects the K nearest neighbors and uses majority voting or average values to suggest the most relevant items.
Real-world example: Netflix uses KNN to recommend movies based on user viewing history. The workflow of KNN in recommendation systems can be described as:
- Data collection:
- Record user behavior, e.g., watched movies, ratings, viewing time, and favorite genres.
- Store product information, e.g., movie details, genre, director, actors, and average community ratings.
- Data preprocessing:
- Standardize data to calculate distances accurately.
- Transform data into a user–item matrix.
- Distance calculation: Use distance metrics like Euclidean distance or cosine similarity to measure similarity between users or items.
- Finding K nearest neighbors: Select the K most similar users or items based on calculated distances.
- Making recommendations:
- Use majority vote or average ratings from K neighbors to suggest new items.
- Example: If 3 out of 5 similar users rated a movie highly, KNN recommends it to the current user.
Spam Detection
In spam detection systems, the KNN classifier helps classify emails or messages as spam or non-spam based on similarity with known samples. The algorithm measures the distance between a new email and training emails using features such as keywords, frequency of terms, or metadata.
Workflow:
- Data collection:
- Gather labeled emails: spam and non-spam.
- Extract features: keywords, number of links, subject line, term frequency.
- Data preprocessing:
- Convert emails into feature vectors (e.g., bag-of-words or TF-IDF).
- Standardize data for accurate distance calculation.
- Distance calculation: Use Euclidean distance or cosine similarity to measure similarity between new and training emails.
- Finding K nearest neighbors: Select the K closest emails to the new email.
Classification: Apply majority voting: if most K neighbors are spam, classify the new email as spam.
Real-world example: Gmail uses KNN combined with other algorithms to filter spam efficiently.
Customer Segmentation
For customer segmentation, KNN helps group customers based on shopping behavior, preferences, or demographic data. The algorithm measures similarity between a new customer and existing customers.
Workflow:
- Data collection: Gather customer data: age, gender, purchase history, website behavior.
Data preprocessing:- Standardize numerical data and encode categorical data.
- Transform into a customer feature matrix.
- Distance calculation: Use Euclidean or Minkowski distance to measure similarity between customers.
- Finding K nearest neighbors: Select the K closest customers to the target customer.
Segmentation: Determine the customer group based on majority vote or feature averaging.
Real-world example: Online retailers like Amazon use KNN to segment customers and deliver personalized promotions.
Voice Recognition
In voice recognition, KNN classifiers are used to identify speakers or recognize words based on similarity with stored voice samples. The algorithm measures distance using audio features such as MFCC, pitch, or formants.
Workflow:
- Data collection:
- Record voices from multiple speakers or sample words.
- Extract audio features: MFCC, pitch, energy.
- Data preprocessing:
- Standardize audio features.
- Transform into feature vectors for distance calculation.
- Distance calculation: Use Euclidean or cosine distance to measure similarity between the new voice sample and training samples.
Finding K nearest neighbors: Select the K closest voice samples.
Recognition: Apply the majority vote to identify the speaker or the spoken word.
Real-world example: Systems like Apple Siri or Google Assistant use KNN combined with other techniques for voice recognition.
Advantages Of The K Nearest Neighbor Algorithm
The next step is to analyze the advantages of the k nearest neighbor algorithm to understand why this method remains highly popular in machine learning. Below are the key strengths of the KNN classifier:
Simple And Easy To Understand
Unlike many complex machine learning algorithms, the KNN classifier operates on a very straightforward principle – “finding the nearest neighbors.” When making a prediction, the algorithm simply measures the distance between a new data point and the points in the training set. Anh then selects the K nearest neighbors to determine the output.
This simplicity makes the nearest neighbor algorithm extremely beginner-friendly. Students or practitioners who are new to machine learning can quickly understand the core concept without requiring advanced mathematical knowledge.
No Complex Model Training Required
Another significant advantage of the nearest neighbor algorithm is that it does not require a complicated training process like many other machine learning models. Instead of building models over multiple epochs, optimizing gradients, or fine-tuning hyperparameters, the KNN classifier follows a “lazy learning” approach.
In this method, the training data is simply stored. When a new data point arrives, the algorithm calculates distances directly to all training instances and produces the result.
Suitable For Multiple Data Types
The KNN classifier can work with numerical data, categorical data, and even mixed data containing multiple feature types.
For example, in a customer dataset, the features might include age (numerical), gender (categorical), and shopping behavior (mixed attributes). The k nearest neighbors algorithm is capable of computing distances across these feature types and combining them effectively to perform classification or prediction.
Scalable With Variants
Although the standard k nearest neighbor algorithm is simple, it can be scaled and extended to handle more complex real-world problems.
For instance, in large datasets, searching for the K nearest neighbors can be computationally expensive. To overcome this, several optimized variants have been developed, including KD-Tree, Ball-Tree, and Approximate Nearest Neighbors, which significantly speed up the search process while maintaining accuracy.
Disadvantages Of The Nearest Neighbor Algorithm
Although the KNN classifier is simple and effective, it also comes with some significant limitations. Therefore, understanding the disadvantages of the nearest neighbor algorithm is essential to apply and optimize the KNN classifier effectively in real-world scenarios.

High Computational Cost For Large Datasets
One of the major disadvantages of the nearest neighbor algorithm is its high computational cost when applied to large datasets. This is because the KNN classifier belongs to the “lazy learning” category, meaning there is no prior model training.
Instead, when a new data point appears, the algorithm must calculate the distance from this point to all points in the training set to determine the K nearest neighbors.
Sensitive To Noise And Outliers
In the KNN classifier, the classification decision is directly based on the K nearest neighbors. If some of these points are mislabeled or are outliers, the prediction results can be easily skewed. This is particularly critical when K is small, as even one noisy point can completely change the classification outcome.
Example: In a disease classification task, if a patient sample is mislabeled, it may become the “nearest neighbor” and lead to incorrect predictions for a new patient.
To reduce the impact of noise and outliers, common approaches include:
- Data preprocessing: removing or handling noisy data.
- Using Weighted KNN: assigning higher weights to closer neighbors and lower weights to distant ones, thereby reducing the influence of outliers.
Requires Feature Scaling
A common drawback of the KNN classifier is the mandatory need for feature scaling to achieve accurate classification. This is because the nearest neighbor algorithm relies on distances between data points. If features have different scales, those with larger values will dominate the distance calculation.
Example: In a customer dataset with age (20–60) and income (5,000–100,000), when calculating Euclidean Distance, the income attribute will dominate, overshadowing the importance of age.
Difficult To Choose Optimal K
Determining the optimal K value is one of the biggest challenges in the disadvantages of the nearest neighbor algorithm. Choosing the right K helps the KNN classifier balance accuracy and generalization, but it remains difficult in practice.
Example: With K=1, a single outlier nearby can lead to incorrect predictions. Conversely, with K=100 in a small dataset, the classification may become overly “averaged” and inaccurate.
Conclusion
The K Nearest Neighbor algorithm remains a flexible tool in machine learning, ideal for businesses seeking both accuracy and simplicity in predictive analytics. Whether for recommendation systems, spam detection, or customer segmentation, KNN enables businesses to make data-driven decisions efficiently. Contact MOR Software today to discover how KNN can optimize your analytics and drive smarter business outcomes.
"Evolution is not a destination, it is a disciplined journey of innovation."
Phung Van Tu


CEO MOR AI
MOR SOFTWARE
Frequently Asked Questions (FAQs)
When to use K Nearest Neighbour?
Use the K Nearest Neighbor Algorithm for classification or regression when data is labeled and relationships are nonlinear.
Why is KNN called a lazy learner?
K Nearest Neighbor Algorithm is called a lazy learner because it stores all training data and performs computation only during prediction.
Is KNN parametric or nonparametric?
No, the K Nearest Neighbor Algorithm is nonparametric because it does not assume any specific data distribution.
Is KNN regression or classification?
K Nearest Neighbor Algorithm can perform both regression and classification tasks.
Is KNN good for large datasets?
No, the K Nearest Neighbor Algorithm is inefficient for large datasets due to the high computational cost of distance calculations.
Is KNN machine learning?
Yes, the K Nearest Neighbor Algorithm is a supervised machine learning algorithm that predicts outcomes based on labeled training data.
Does Netflix use KNN?
Yes, Netflix uses K Nearest Neighbor Algorithm in its recommendation systems to identify similar users and suggest relevant content.
Share




Rate this article
0
over 5.0 based on 0 reviews
Your rating on this news:
Name
*Email
*Write your comment
*Send your comment
1