Top 10+ Natural Language Processing Tools in 2026

Choosing the right natural language processing tools can turn messy text data into real business value. Many still struggle with this challenge. This MOR Software’s guide will walk you through the top options for 2026 to help you make smarter decisions with AI.
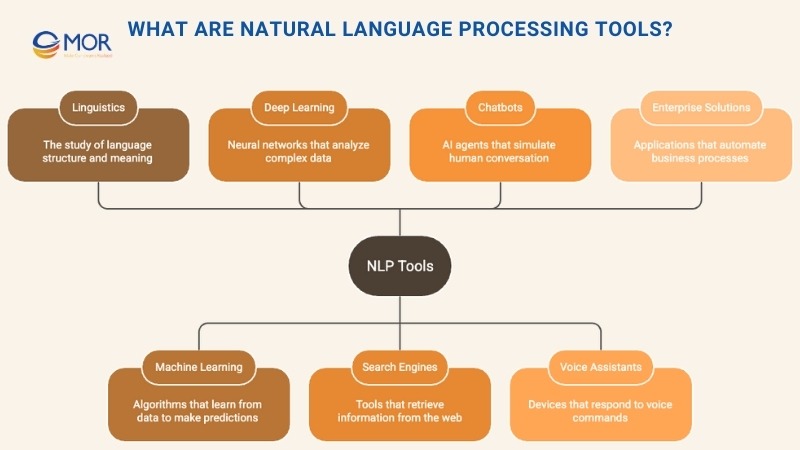
What Are Natural Language Processing Tools?
Natural language processing (NLP) is a branch of computer science and artificial intelligence that focuses on teaching machines how to understand and respond to human language. It brings together computational linguistics, machine learning, and deep learning to let systems process text and speech in ways that feel natural.
These methods allow computers to read, interpret, and generate words by combining rule-based language models with statistical and algorithmic learning. Over the past decade, progress in this field has paved the way for modern generative AI, where large language models not only answer questions but also produce meaningful content across text, audio, and even images.
Analysts at IDC estimate enterprises will invest about 307 billion USD in AI in 2025, rising to 632 billion USD by 2028. This shows how quickly these capabilities are moving into mainstream operations.
You already interact with nlp natural language processing tools every day. They drive search engines, power virtual assistants like Siri and Alexa, guide chatbots in customer service, and even make voice-enabled GPS systems possible. From autocomplete in your email client to conversational interfaces, the influence of NLP is everywhere.
Beyond consumer applications, natural language processing tools are becoming central to business solutions. They help automate workflows, improve customer engagement, and unlock productivity gains across industries. For enterprises, adopting these tools means more than convenience. It’s about reshaping how teams operate, collaborate, and deliver value.
>>> Explore how machine learning works, explain the key steps behind the process, and show how companies can apply it to solve real problems.
How Do Natural Language Processing Tools Work?
Natural language processing tools function by applying a series of computational methods that allow machines to read, interpret, and generate human language in a structured way. The process is often described as a pipeline, where text passes through multiple stages before it is ready for deeper analysis or model training.
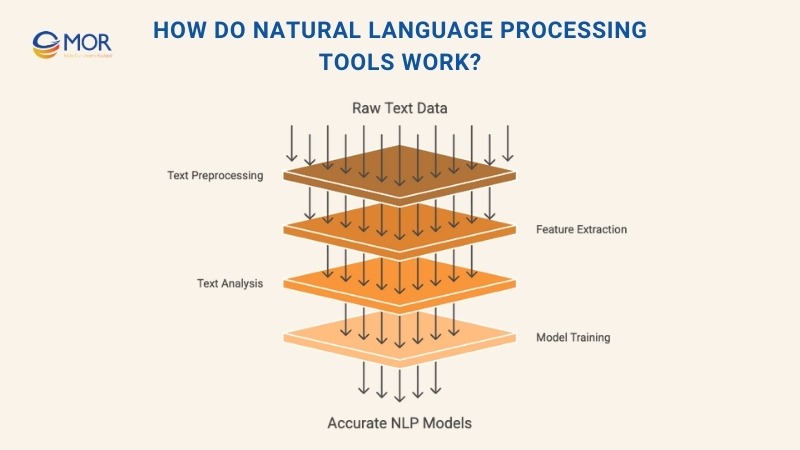
Preprocessing The Text
Preprocessing is the foundation of any natural language processing tool because raw text must be simplified before algorithms can work effectively. The process usually starts with tokenization, which splits sentences into smaller units such as words or phrases. This makes large blocks of language easier to manage.
Then comes lowercasing, a step that converts all text into the same case so that “Apple” and “apple” are treated as identical.
Another common step is removing stop words, terms like “is,” “and,” or “the” that appear often but add little meaning to analysis. Tools may also apply stemming or lemmatization, which reduce words to their base form.
For example, “running,” “ran,” and “runs” are mapped to “run,” making it easier for systems to identify patterns. Finally, cleaning strips out punctuation, special characters, and stray numbers that would otherwise interfere with interpretation.
Once this preprocessing is complete, the cleaned data is ready for nlp software or machine learning models to analyze more effectively, ensuring consistency and accuracy in the next stages of language understanding.
Extracting Features From Text
After cleaning, text must be converted into a format machines can process. Feature extraction is the step where raw language is transformed into structured numerical data, giving algorithms a way to measure and compare words.
Traditional natural language processing tools and techniques rely on approaches like Bag of Words and TF-IDF. These methods count how often terms appear in a document and adjust for how common they are across larger datasets. While simple, they provide a useful baseline for many applications.
More advanced techniques introduce word embeddings, such as Word2Vec or GloVe. These represent words as vectors in a continuous space, making it possible to capture meaning and relationships between terms.
Modern nlp tool designs go further with contextual embeddings, which adjust word meaning based on surrounding text. This creates deeper, more accurate representations that power today’s most effective models.
Analyzing The Text
Once features are extracted, text analysis applies computational methods to uncover meaning and patterns within the data. This stage transforms unstructured language into structured insights that can drive smarter applications.
Core techniques include part-of-speech tagging, which assigns grammatical roles to words, and named entity recognition, which identifies people, places, dates, and other key terms. Dependency parsing digs into sentence structure, mapping how words relate to one another. Sentiment analysis measures tone, classifying language as positive, negative, or neutral.
For broader insights, topic modeling uncovers recurring themes across documents. At a deeper level, natural language understanding focuses on interpreting intent and meaning, allowing systems to distinguish between different uses of the same word or recognize similar ideas expressed in varied ways. With these methods, natural language processing AI tools transform plain text into actionable knowledge.
Training The Models
Once the data has been prepared and features extracted, it moves into the stage of model training. Here, machine learning algorithms study patterns, relationships, and structures within the text.
As training progresses, the model adjusts its parameters to reduce mistakes and sharpen its predictions. When complete, the trained model can analyze new inputs, classify information, or generate responses with increasing accuracy.
Performance does not stop at the first run. Models are evaluated, validated, and fine-tuned repeatedly, ensuring they remain relevant and precise in real-world use cases. This cycle of testing and adjustment is what allows natural language processing tools python and other environments to deliver dependable outcomes.
Several software libraries support this process. The Natural Language Toolkit (NLTK), written in Python, provides a suite of functions for tokenization, tagging, parsing, and semantic reasoning.
TensorFlow, an open-source framework, is widely used to build and train machine learning models for NLP tasks. With the right nlp platforms, tutorials, and certifications, developers can continuously improve their skills and build more effective applications.
Top 12 Best Natural Language Processing Tools To Use In 2026
The market is full of options, but some natural language processing tools stand out for their reliability and real-world impact. Below, we’ve highlighted the top 12 to consider in 2026.

SpaCy
SpaCy is a leading open-source library in Python built for advanced natural language processing tools. Known for its speed and accuracy, it supports a wide range of tasks, including tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and lemmatization. It also provides capabilities for deep learning, making it useful for sentiment analysis, classification, entity linking, and word embeddings.
Designed with production in mind, SpaCy can manage large volumes of text without losing performance, which makes it a preferred nlp software choice for enterprises.
Key strengths of SpaCy include:
- High efficiency, capable of processing millions of words in seconds.
- Simple, consistent API that makes customization straightforward.
- Broad multilingual coverage, with support for English, French, German, Spanish, Portuguese, Italian, Dutch, and many others.
- Strong ecosystem of extensions and integrations, such as spaCy-Transformers, spaCy-AllenNLP, and spaCy-stanza.
- Active developer community with detailed documentation, tutorials, and learning resources.
Practical use cases for SpaCy include:
- Creating AI-driven chatbots and conversational assistants.
- Extracting skills, roles, and experience data from resumes and job listings.
- Analyzing customer reviews or survey responses for actionable feedback.
- Generating summaries, captions, and natural language outputs.
- Building intuitive, language-based interfaces and applications.
IBM Watson
IBM Watson is a cloud-based platform that provides a suite of AI and natural language processing tools tailored for businesses across many sectors. It allows organizations to design, deploy, and scale intelligent applications without building everything from scratch. With its broad capabilities, Watson has become a trusted option for enterprises looking to integrate nlp platforms into daily operations.
Key features and advantages of IBM Watson include:
- High scalability and reliability, built to manage large datasets and demanding workloads.
- Flexible services with customization options, giving users the ability to adapt tools to their specific business needs.
- Strong focus on security and compliance, ensuring strict data privacy standards are met.
- Accessible pricing tiers designed to suit both small teams and large enterprises.
- Ongoing innovation, powered by the latest AI and NLP research to keep solutions modern and competitive.
Common use cases of IBM Watson include:
- Elevating customer service by powering chatbots and support automation.
- Strengthening business intelligence with deeper analytics and decision support.
- Automating content creation, editing, and curation.
- Supporting sales and marketing optimization with advanced audience insights.
- Facilitating multilingual and cross-cultural communication for global companies.
Google Cloud
Google Cloud is a flexible cloud computing platform that offers a wide range of AI and natural language processing tools for businesses in different industries. It gives teams the ability to build, run, and scale applications using Google’s global infrastructure, making it a go-to option for companies wanting speed and reliability.
Key features and benefits of Google Cloud include:
- Strong processing power capable of managing large and complex datasets with ease.
- Simple integration and an intuitive API that makes it user-friendly.
- Reliable scalability to support high volumes of traffic and requests.
- Built-in security and compliance standards to safeguard sensitive data.
- Cost-effective pricing models tailored for organizations of different sizes and needs.
Practical use cases of Google Cloud include:
- Developing chatbots and conversational autonomous AI agents.
- Analyzing customer feedback and reviews for better insights.
- Translating and localizing content across multiple languages.
- Producing automated summaries, captions, and reports.
- Creating natural language-driven applications and interfaces.
Gensim
Gensim is an open-source Python library focused on unsupervised topic modeling and natural language processing tools. It delivers fast, scalable methods for tasks like text preprocessing, word embeddings, topic modeling, and document similarity. Because of its versatility, Gensim is widely used in both academic research and industry projects, supporting developers as they explore advanced text analysis applications.
Beyond its core functions, Gensim also integrates with deep learning models for text generation, summarization, and translation. Whether you are a researcher, data scientist, or working with multilingual content, this library offers powerful ways to process and interpret large volumes of text.
Key features and benefits of Gensim include:
- High processing speed, capable of handling millions of words per second.
- Clear and consistent API that is easy to customize.
- Multilingual coverage across English, French, German, Spanish, Portuguese, Italian, Dutch, and more.
- Strong ecosystem of integrations like gensim-data, gensim-summarization, and gensim-server.
- Active community support, with thorough documentation and tutorials available.
Practical use cases of Gensim include:
- Extracting topics and themes from large text collections.
- Comparing similarity and distance between documents.
- Producing natural language summaries and abstracts.
- Translating or paraphrasing content across multiple languages.
- Building applications with natural language-driven interfaces.
MonkeyLearn
MonkeyLearn is a cloud-based platform that delivers a broad range of AI and natural language processing tools for businesses across different sectors. It simplifies the process of building, deploying, and scaling intelligent applications, making it accessible even for non-technical users.
Key features and benefits of MonkeyLearn include:
- User-friendly interface that lets you create and train custom models or build website without coding.
- Scalable and reliable infrastructure capable of handling complex and large datasets.
- Flexible integration with platforms like Zapier, Google Sheets, Zendesk, Slack, and others.
- Strong focus on security and compliance, following best practices in data protection.
- Cost-effective pricing options designed to suit diverse business needs.
Common use cases of MonkeyLearn include:
- Analyzing customer feedback, reviews, and survey responses.
- Extracting structured information from invoices, receipts, and other documents.
- Producing headlines, captions, or short pieces of text content.
- Turning unstructured data into engaging visualizations.
- Building natural language-powered business applications and interfaces.
Aylien
Aylien is a cloud-based platform that delivers advanced AI and natural language processing tools for enterprises in multiple industries. It helps users design, deploy, and scale intelligent solutions quickly, making it a valuable choice for handling complex data-driven tasks.
Key features and benefits of Aylien include:
- High processing power capable of managing large and complex datasets efficiently.
- Simple and intuitive API that makes integration straightforward.
- Strong scalability and reliability to manage heavy traffic and requests.
- Built-in security and compliance practices to safeguard sensitive data.
- Continuous innovation, fueled by the latest advances in AI and NLP research.
Typical use cases of Aylien include:
- Analyzing customer feedback, reviews, and survey responses.
- Extracting insights from news articles, blogs, and online sources.
- Generating summaries, headlines, and concise natural language outputs.
- Translating and localizing content for global audiences.
- Building business applications with language-driven interfaces.
Amazon Comprehend
Amazon Comprehend is a managed cloud service that delivers AI-driven natural language processing tools for enterprises across different sectors. It allows users to quickly build, deploy, and scale applications that understand and interpret text, all while running on Amazon’s secure infrastructure.
Key features and benefits of Amazon Comprehend include:
- Strong processing power for handling large, complex datasets with speed and accuracy.
- Simple integration through an intuitive API, making it easy to implement in existing systems.
- High scalability and reliability to support heavy workloads and fluctuating traffic.
- Built-in compliance and data protection standards to ensure security.
- Flexible pricing models that make it cost-effective for businesses of all sizes.
Common use cases of Amazon Comprehend include:
- Analyzing customer reviews, survey results, and feedback.
- Extracting structured information from unstructured documents and forms.
- Creating automated text summaries, captions, and headlines.
- Translating and localizing written content for global audiences.
- Developing business applications with natural language-driven interfaces.
NLTK
NLTK, short for the Natural Language Toolkit, is a popular open-source Python library built for natural language processing tools. It provides a wide collection of methods to handle tasks such as tokenization, part-of-speech tagging, named entity recognition, stemming, lemmatization, parsing, and chunking. Because of its flexibility, it has become a standard choice for both education and research.
The library also includes access to well-known corpora and resources, including WordNet, Brown Corpus, and the Movie Reviews Corpus. While it is best suited for small to medium-scale projects, NLTK remains one of the most widely adopted nlp natural language processing tools in academic environments.
Key features and benefits of NLTK include:
- Comprehensive coverage of a wide range of NLP concepts and techniques.
- Beginner-friendly API that is clear and consistent.
- Multilingual support, covering English, French, German, Spanish, Portuguese, Italian, Dutch, and more.
- Rich ecosystem with tools like nltk-trainer, nltk-contrib, and nltk-data.
- Strong community with extensive documentation, guides, and tutorials.
Typical use cases of NLTK include:
- Teaching and learning key NLP principles and methods.
- Experimenting with datasets and testing NLP models.
- Building prototypes and proofs of concept for language applications.
- Creating applications and interfaces powered by natural language.
Stanford CoreNLP
Stanford CoreNLP is a widely used open-source Java library built for natural language processing tools. It provides a reliable and accurate framework for key NLP tasks like tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and coreference resolution. With support for deep learning, it also extends to classification, relation extraction, and even machine translation, making it suitable for advanced projects.
Designed for production environments, Stanford CoreNLP can handle large datasets and complex workloads while maintaining strong performance. Its versatility has made it a popular choice for researchers and businesses alike.
Key features and benefits of Stanford CoreNLP include:
- High accuracy and robustness, capable of processing extensive text efficiently.
- Customizable API that remains clear and consistent across tasks.
- Support for multiple languages, including English, Arabic, Chinese, French, German, Spanish, and others.
- Active ecosystem with tools such as StanfordNLP, CoreNLP Server, and CoreNLP Python.
- Strong community support with comprehensive documentation and tutorials.
Common use cases of Stanford CoreNLP include:
- Creating chatbots and conversational AI systems.
- Extracting structured data from articles, blogs, and online sources.
- Analyzing customer feedback, survey responses, and reviews.
- Generating text summaries, captions, and natural language outputs.
- Building enterprise applications with language-based interfaces.
TextBlob
TextBlob is an open-source Python library designed to make natural language processing tools more accessible. It provides a straightforward interface for common NLP tasks, including tokenization, part-of-speech tagging, noun phrase extraction, sentiment analysis, spelling correction, and translation. With its beginner-friendly design, it is especially useful for students, hobbyists, and early-stage projects.
The library also connects with popular corpora and resources like WordNet, Brown Corpus, and the Movie Reviews Corpus. As one of the simpler best natural language processing tools, TextBlob is well-suited for small to medium text datasets where ease of use is just as important as functionality.
Key features and benefits of TextBlob include:
- Simple and elegant design with a user-friendly API.
- Easy to learn, with consistent functions across tasks.
- Multilingual support for English, French, German, Spanish, Portuguese, Italian, Dutch, and more.
- Strong ecosystem of add-ons like textblob-fr, textblob-de, and textblob-aptagger.
- Detailed documentation and active community support for learning and troubleshooting.
Typical use cases of TextBlob include:
- Teaching and learning NLP basics in classrooms or workshops.
- Experimenting with text datasets and trying out nlp models.
- Creating prototypes and proof-of-concept applications.
- Developing applications with simple natural language interfaces.
OpenNLP
OpenNLP is an open-source Java library created for natural language processing tools. It provides a modular and flexible framework for a variety of NLP tasks, including tokenization, part-of-speech tagging, named entity recognition, chunking, parsing, and coreference resolution. Its design makes it suitable for production environments where reliability and scalability are required.
The library also connects with well-known corpora and datasets such as CoNLL, Penn Treebank, and OntoNotes. With its adaptability, OpenNLP can handle complex text processing tasks and build pipelines tailored to specific business needs.
Key features and benefits of OpenNLP include:
- Modular and flexible architecture that allows users to design custom NLP pipelines.
- Consistent API that makes it simple to use and integrate into applications.
- Multilingual support, including English, French, German, Spanish, Portuguese, Italian, Dutch, and more.
- Expansive ecosystem with integrations like opennlp-tools, opennlp-uima, and opennlp-brat.
- Active community backing with detailed documentation and tutorials.
Typical use cases of OpenNLP include:
- Building conversational agents and chatbots.
- Extracting structured information from forms and documents.
- Analyzing customer reviews and survey data.
- Producing automated text summaries and captions.
- Developing enterprise applications powered by natural language.
Textacy
Textacy is an open-source Python library built to extend the functionality of natural language processing tools. It provides a high-level interface for both common and advanced NLP tasks, including text preprocessing, analysis, extraction, generation, summarization, and visualization. Because of its flexibility, it has become a popular choice for researchers and developers experimenting with complex text workflows.
The library also integrates with widely used resources such as Wikipedia, Reddit, and Common Crawl. While best suited for research and exploration, Textacy can efficiently manage small to medium datasets, making it a practical tool for both academic and applied projects.
Key features and benefits of Textacy include:
- High-level interface with a simple, user-friendly API.
- Easy to adopt and consistent across various NLP tasks.
- Multilingual support covering English, French, German, Spanish, Portuguese, Italian, Dutch, and more.
- Strong ecosystem of add-ons like textacy-data, textacy-spacier, and textacy-viz.
- Backed by an active community that provides tutorials, documentation, and ongoing updates.
Typical use cases of Textacy include:
- Teaching and learning NLP methods in educational settings.
- Experimenting with datasets and testing different implement natural language processing models.
- Designing prototypes and proof-of-concept applications.
- Creating applications with natural language-driven interfaces.
Comparison Table of 12 Natural Language Processing Tools (2026)
Tool | Pricing Model | Languages Supported | Main Use Cases |
SpaCy | Free, Open Source | 10+ (EN, FR, DE, ES, PT, IT, NL, etc.) | Chatbots, resume parsing, feedback analysis, text summarization |
IBM Watson | Paid, Cloud-based | 20+ | Customer service, BI, content automation, marketing, multilingual communication |
Google Cloud NLP | Paid, Cloud-based | 100+ (broad coverage) | Chatbots, sentiment analysis, translation, search improvement |
GenSim | Free, Open Source | 10+ | Topic modeling, similarity measurement, summaries, translation |
MonkeyLearn | Paid, Cloud-based | 6+ | Customer feedback, invoice parsing, headline generation, visualization |
Aylien | Paid, Cloud-based | 10+ | News analytics, review analysis, summarization, translation |
Amazon Comprehend | Paid, Cloud-based | 15+ | Document analysis, reviews, text summarization, translation, entity detection |
NLTK | Free, Open Source | 12+ | Teaching NLP, research, prototyping, experimenting with models |
Stanford CoreNLP | Free, Open Source | 8+ (EN, AR, ZH, FR, DE, ES, etc.) | Chatbots, information extraction, sentiment analysis, translation |
TextBlob | Free, Open Source | 10+ | Education, quick prototyping, sentiment analysis, text translation |
OpenNLP | Free, Open Source | 10+ | Chatbots, document processing, entity recognition, text classification |
Textacy | Free, Open Source | 10+ | Research, text preprocessing, prototyping, visualization, summarization |
Key Benefits Of Using Natural Language Processing Tools
Natural language processing tools make it possible for people to interact with machines in everyday language, creating smoother collaboration and smarter automation. This delivers measurable value across industries and use cases.
- Automating repetitive workflows
- Stronger data insights
- Smarter search capabilities
- Automated content generation
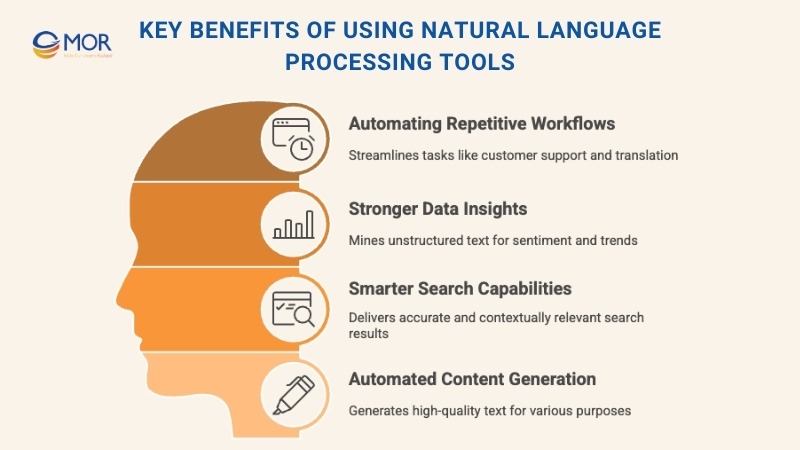
Automating Repetitive Workflows
One of the biggest advantages of NLP is its ability to automate tasks that would otherwise consume hours of manual work. Chatbots powered by natural language processing AI tools can resolve common support questions instantly, allowing customer service teams to focus on complex issues.
In document-heavy environments, NLP can classify files, extract relevant details, and summarize key points, significantly reducing errors and saving time. Language translation also becomes more accurate, enabling businesses to convert text across languages without losing meaning or intent.
Stronger Data Insights
Natural language processing tools expand the way businesses analyze information by pulling meaning from unstructured text sources like reviews, social media, or news articles.
Through text mining techniques, NLP can reveal patterns, trends, and sentiments that might otherwise stay hidden in massive datasets. Sentiment analysis goes deeper, identifying emotions, attitudes, or even sarcasm, helping systems route communications to the right person or department for faster responses.
With these capabilities, companies gain a clearer picture of customer behavior, shifts in market conditions, and public perception. Beyond that, nlp tool functions like categorization and summarization make it easier to sort through large text collections, highlight what matters most, and support smarter, data-driven decision-making.
Many organizations now manage petabyte-scale unstructured data, and in 2024 almost half reported storing more than 5 PB. Meanwhile, 57% said preparing data for AI was their top business challenge.
Smarter Search Capabilities
Another strength of natural language processing tools is their ability to improve how search systems work. Instead of depending only on exact keyword matches, NLP-powered search engines interpret the intent behind a query, delivering results that are more accurate and relevant to context. This makes it possible to surface the right information even when the question is vague or complex.
Recent research found that knowledge workers globally are spending roughly a quarter of their week just tracking down information. This highlights why intent-aware search matters.
For businesses, this translates into a better user experience across web searches, internal document retrieval, and enterprise databases. By understanding meaning rather than just words, nlp software helps users find what they need faster and with greater accuracy.
Automated Content Generation
Modern natural language processing tools make it possible to generate text that feels natural and human-like. Pre-trained models such as GPT-4 can create a wide range of outputs, from reports and articles to marketing copy, product descriptions, and even creative writing, all based on user prompts.
These tools are also used for everyday automation, including drafting emails, writing social media posts, or preparing legal documentation. By recognizing tone, context, and style, they ensure the output is coherent and aligned with the intended message. For businesses, this means faster production of quality content with less manual effort, making best natural language processing tools a valuable part of modern workflows.
Industry Applications Of Natural Language Processing Tools
Today, natural language processing tools are applied in nearly every sector, driving both speed and accuracy in critical processes.

Finance
In the financial world, even the smallest delay can affect outcomes. NLP accelerates the extraction of insights from statements, regulatory filings, news reports, and even social media chatter. By processing this data instantly, natural language processing tools and techniques help traders, analysts, and institutions act on opportunities with greater confidence.
A McKinsey-referenced industry snapshot shows that 91% of financial services firms are either using AI or assessing it. This reflects broad momentum to embed these capabilities in day-to-day decisioning.
Healthcare
Medical knowledge grows faster than most professionals can track. NLP-powered systems assist by analyzing electronic health records, lab notes, and research publications at scale.
This supports informed decision-making, early detection of illnesses, and in some cases, preventive care. For hospitals and research institutions, these tools make vast medical knowledge more usable and actionable.
In primary care, an ambient AI scribe cut time spent in clinical notes by 20.4% and reduced after-hours work by 30% per workday in a randomized trial. This shows how language technology can free up clinician time for patients.
Insurance
In the insurance sector, natural language processing tools can review claims data to uncover patterns that point to fraud risks, inconsistencies, or inefficiencies in workflows. By flagging these issues early, insurers improve accuracy and streamline operations, allowing employees to focus on higher-value tasks instead of manual reviews.
The Coalition Against Insurance Fraud estimates that fraud costs businesses and consumers in the United States about 308.6 billion USD each year. So even modest detection gains create meaningful savings.
Legal
Legal work often involves analyzing large volumes of documents, case histories, and precedents. NLP helps automate discovery by organizing unstructured text, identifying critical details, and speeding up the review process. With nlp software, firms can ensure no relevant information is overlooked while reducing the time required for case preparation.
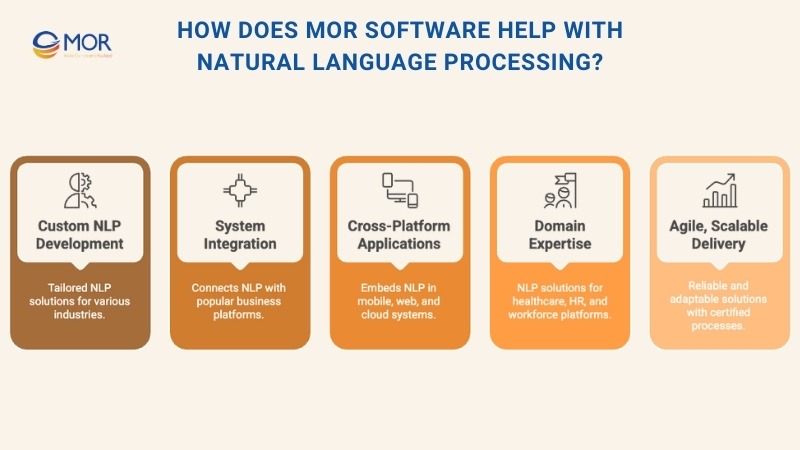
How Does MOR Software Help With Natural Language Processing?
At MOR Software, we build practical custom machine learning solutions that integrate natural language processing into real business workflows. Our teams have delivered projects across healthcare, finance, HR, and eCommerce, where NLP is central to improving communication, automation, and decision-making.
We provide:
- Custom NLP development: From sentiment analysis in customer feedback to intelligent chatbots for patient support, our engineers design models tailored to each industry.
- Integration with enterprise systems: We connect NLP solutions with Salesforce, ERP, and legacy platforms, ensuring data flows seamlessly across channels.
- Cross-platform applications: Our experience in mobile and web development means NLP capabilities can run inside apps, dashboards, and cloud systems.
- Domain-specific expertise: Case studies show our work in healthcare consultations, HR platforms, and workforce management. Each of these required advanced data handling, where NLP tools add real value.
- Agile and scalable delivery: With ISO-certified processes, global delivery centers, and expertise in AI technologies, we create solutions that grow with your business.
Whether it’s automating document processing, improving customer experience with smarter chatbots, or unlocking insights from large text datasets, MOR Software provides the technical foundation and industry knowledge to make NLP adoption a success.
Common Challenges In Natural Language Processing Tools
Even the most advanced natural language processing tools are far from flawless, much like human communication itself. Language is full of irregularities, cultural nuances, and ambiguities that make it difficult for systems to consistently identify intent or meaning.
While people spend years learning language and still face misunderstandings, developers must train AI applications to interpret these complexities accurately enough to be useful. Along the way, organizations need to be aware of risks that come with building and deploying these solutions.

Biased Training Data
Like all AI models, NLP systems are only as good as the data they learn from. If training data contains bias, the outputs will inevitably reflect that bias. This problem becomes more noticeable in sensitive areas like government services, healthcare, or HR processes, where diversity of users is high.
Datasets scraped from the internet are especially prone to these issues, raising concerns about fairness and accuracy. For teams looking to implement natural language processing, handling bias in training data is one of the biggest challenges to address.
Misinterpretation Of Input
A common risk with natural language processing tools is the classic “garbage in, garbage out” problem. For instance, speech recognition systems are designed to convert spoken words into text, but accuracy drops when inputs are less than clear.
Obscure dialects, heavy slang, homonyms, poor grammar, or fragmented sentences can all confuse NLP models. Background noise, mispronunciations, or mumbled speech add further complications, leading to errors that affect the reliability of results from even the most advanced nlp tool.
Constantly Changing Vocabulary
Human language never stands still. New words emerge, borrowed terms enter daily use, and grammar rules shift, or are deliberately bent. When this happens, natural language processing tools may struggle. Models can either attempt a guess or return uncertainty, both of which create complications in accuracy and reliability.
Difficulty With Tone Or Sarcasm
Words alone rarely tell the whole story. Meaning can change dramatically depending on tone, emphasis, or delivery. Sarcasm, exaggeration, and stress on certain words can shift intent in ways that are difficult for machines to catch. Without the help of context like body language or vocal cues, even advanced nlp platforms may misinterpret what was actually meant, limiting the effectiveness of semantic analysis.
Conclusion
The right natural language processing tools turn unstructured text into clear business value, powering automation, smarter search, and better decisions. At MOR Software, we bring NLP into real workflows across healthcare, finance, HR, and eCommerce. With certified processes and industry expertise, we deliver solutions that scale with your growth. As AI adoption expands in 2026, now is the time to act. Contact us to get started.
"Evolution is not a destination, it is a disciplined journey of innovation."
Phung Van Tu


CEO MOR AI
MOR SOFTWARE
Frequently Asked Questions (FAQs)
Is ChatGPT an NLP?
Yes. ChatGPT is an application of Natural Language Processing (NLP). It is designed to understand and generate human language automatically using advanced algorithms.
What is an example of a natural language processing tool?
Examples of NLP tools include everyday features like autocorrect, autocomplete, and predictive text. These functions suggest or complete words based on what you type, much like how search engines predict your queries.
What is NLP and NLTK?
NLTK, or the Natural Language Toolkit, is a Python library that provides tools for symbolic and statistical natural language processing in English. It includes resources for tasks such as classification, tokenization, stemming, tagging, parsing, and semantic analysis.
What is NLP and example?
Natural Language Processing (NLP) is the technology that enables computers to understand and interact using human language. Common examples are chatbots, spell check, speech recognition, autocomplete, and search engines.
What are the four types of NLP?
NLP methods are generally grouped into four categories: statistical approaches, stochastic models, rule-based methods, and hybrid techniques that combine multiple strategies.
Is NLP AI or ML?
NLP and machine learning are both part of artificial intelligence. Machine learning powers many NLP systems, but the two are not identical. NLP is focused on language, while machine learning is a broader field within AI.
What is the difference between NLP and LLM?
NLP is the overall field that covers techniques for processing, interpreting, and generating human language. Large Language Models (LLMs) are a specific type of NLP model that use deep learning and massive datasets to handle many complex language tasks. In short, all LLMs are NLP tools, but NLP also includes many other approaches.
Is Python an NLP?
Python itself is not an NLP technology, but it is the most widely used programming language for NLP projects. It offers many libraries and frameworks that simplify tasks like text analysis, classification, and machine translation.
What are the two major methods of NLP?
The two common approaches are stemming and lemmatization. Stemming reduces words to a root form by trimming endings, while lemmatization returns the proper base form of a word using vocabulary and grammar rules.
Which programming language is best for NLP?
Python is considered the best language for NLP because of its simple syntax, strong community support, and a large number of specialized libraries like NLTK, SpaCy, and Transformers.
Is NLP the same as generative AI?
No. NLP focuses on understanding and processing human language, while generative AI creates new content such as text, images, or audio based on patterns in data. Generative AI often relies on NLP techniques, but the goals are different.
Does NLP require coding?
Yes, some coding knowledge is needed to work with NLP, but you don’t need to be an expert programmer. A basic understanding of Python is usually enough to start using NLP libraries and frameworks.
Is C++ good for NLP?
Yes. C++ is valued for its speed and efficiency, which makes it useful for intensive NLP tasks. Libraries like Boost and Tesseract help developers build fast text-processing and machine learning applications.
Which is better, deep learning or NLP?
They are not directly comparable. NLP is the field of language processing, while deep learning is a technique that can be applied within NLP. Deep learning models handle large datasets well and learn complex patterns, while traditional NLP approaches may struggle with ambiguity like sarcasm or idioms.
Share




Rate this article
0
over 5.0 based on 0 reviews
Your rating on this news:
Name
*Email
*Write your comment
*Send your comment
1