TOP 10 Leading Multimodal AI Models in 2026

Multimodal AI models are redefining how businesses analyze data, make decisions, and serve customers. Yet many leaders still ask: what is multimodal AI and how can it be applied in real business scenarios? In this guide, MOR Software will break down everything you need to know about multimodal systems, their benefits, and their practical uses in 2026.
What Are Multimodal AI Models?
Multimodal AI models are machine learning systems that can process and integrate information from different types of data. These inputs, known as modalities, can include text, images, sound, video, and even sensory signals.
As AI automation goes mainstream, businesses are rapidly adopting these capabilities. McKinsey’s latest global survey found 71% of organizations were regularly using generative AI in at least one function by late 2024, creating fertile ground for multimodal features to move from pilots to production.
Unlike unimodal models that only work with one kind of data, multimodal AI blends several inputs to form richer analysis and generate outputs that feel more complete. For instance, these systems can interpret both text and images together, offering deeper results than working with one source alone. The Stanford AI Index shows that multimodal systems are improving fast. On the new MMMU benchmark alone, their scores jumped by 18.8% points in 2024, which proves they are getting much better at reasoning across different types of data.
Take a simple case: a model receives a picture of a mountain range and produces a descriptive paragraph about its features. The same system could start with a written description and generate a matching image. This cross-channel ability reflects what does multimodal mean in AI, the power to operate across multiple modalities seamlessly.
Earlier releases like ChatGPT, launched in 2022, worked as unimodal AI by focusing only on text through natural language processing. OpenAI expanded this with tools like DALL·E, an early multimodal generative AI, and later GPT-4o, which brought advanced multimodal capabilities into conversational systems.
Through drawing from diverse modality data, these models reach stronger conclusions and provide more reliable outputs. The integration reduces confusion, improves accuracy, and makes the system less dependent on any single channel. If one input is noisy or missing, other data types keep the process stable.
This versatility explains why multi modal models are changing fields like speech recognition, translation, and image analysis. Blending signals leads to higher precision and a clearer understanding of content.
Another key point is user interaction. Multimodal AI meaning includes creating smoother, more natural connections between humans and machines. Virtual assistants that respond to voice and visual prompts are already proving this.
Think of a chatbot that can recommend eyeglass sizes after analyzing a selfie, or a bird app that uses both an uploaded photo and a recorded song to confirm species. These multimodal AI examples show how cross-sensory learning translates into practical, engaging tools.
With stronger accuracy, flexibility, and natural interaction, multimodal AI models stand out as a foundation for business and consumer applications in 2026 and beyond.
How Multimodal AI Models Work
The field of artificial intelligence continues to expand, and one of the most exciting areas is the development of multimodal AI models. Early projects explored audio-visual speech recognition or multimedia indexing, but breakthroughs in deep learning and scalable training methods have pushed research much further. These advances laid the foundation for today’s multimodal generative AI, which blends different forms of data in a single framework.
Now, real-world applications range widely. In healthcare, these systems analyze scans with text-based records for sharper diagnosis. In transportation, computer vision combines with audio and sensor streams to power autonomous vehicles. These examples highlight what is multimodal AI in practice, using diverse inputs for stronger, more adaptable results.
A study from Carnegie Mellon in 2022 outlined three defining traits of multi modal models: heterogeneity, connections, and interactions. Heterogeneity means that each modality is inherently different, such as the contrast between a sentence and a photo of the same scene. Connections capture the shared or complementary information across these inputs. Interactions describe how the inputs work together when fused into a single model.
The main challenge for engineers is integrating varied modality data into one system while preserving each type’s strengths. The Carnegie Mellon paper identified six ongoing technical hurdles: representation, alignment, reasoning, generation, transference, and quantification.
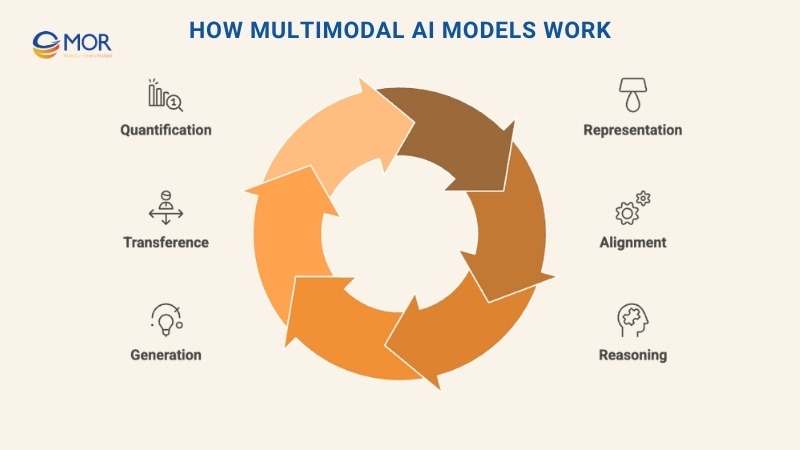
- Representation is about how to encode what is multi modal data so that links between text, images, or sound are captured. Specialized neural networks like CNNs for vision and transformers for text create features that feed into shared embedding spaces.
- Alignment deals with matching content across channels, like syncing spoken words with their position in a video or mapping captions onto images.
- Reasoning focuses on combining evidence from different sources to support multi-step conclusions.
- Generation teaches models to produce new data, an image from a caption or dialogue from a video.
- Transference allows knowledge gained in one input type to be applied to another, often through transfer learning.
- Quantification measures how well models balance and evaluate performance across multiple modalities. On the SWE-bench code benchmark, leading models solved just 4.4% of problems in 2023. By 2024, that number jumped to 71.7%, showing how much better aligned multimodal systems can get when trained effectively.
Adding these complexities makes multimodal systems more advanced than traditional large language models (LLMs). While LLMs rely on transformer-based encoder-decoder designs, multimodal AI expands the architecture with fusion techniques. Fusion may occur early, when inputs are encoded into a shared space; mid, during preprocessing; or late, when separate models generate outputs that are then combined.
In short, multimodal AI models work by weaving diverse channels into unified systems, producing insights and outputs that are richer, more accurate, and closer to human understanding.
Comparing Generative, Unimodal, and Multimodal AI Models
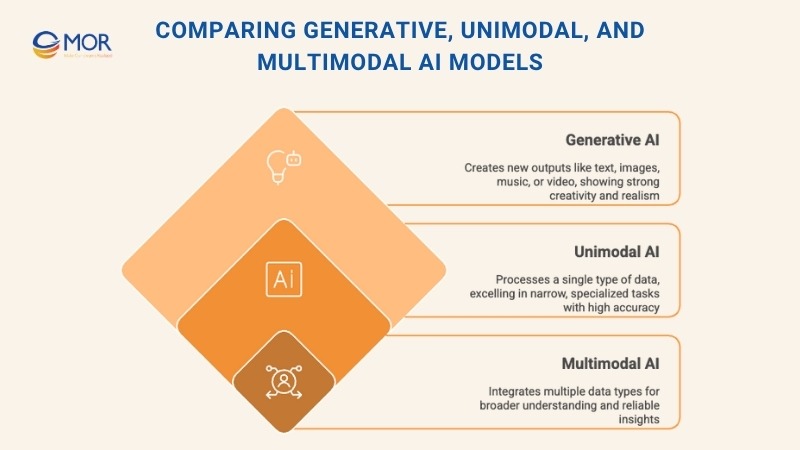
Artificial intelligence can be grouped into different categories depending on how it processes and produces information. Generative AI, unimodal AI, and multimodal AI models share some similarities but are designed for very different goals.
Generative AI focuses on producing new outputs, writing text, generating images, composing music, or creating video clips. Unimodal AI works with a single input type, such as a translation model that only handles text or a vision model trained strictly on images. By contrast, multimodal AI models integrate several data types at once, combining signals from text, visuals, and even audio to deliver richer analysis and more precise results.
This comparison makes it clear why how multimodal used in generative AI is a game-changer. Adding multiple inputs to generative systems makes them more flexible and useful across real-world applications.
Features | Generative AI | Unimodal AI | Multimodal AI Models |
Definition | Systems built to create new data or content | Models that process one form of data | Models that integrate and process more than one type of data |
Primary Use Cases | Writing articles, image generation, creative design | Text translation, image classification, voice recognition | Self-driving, healthcare imaging, advanced security |
Advantages | Strong creativity and realistic outputs | Excellent accuracy in narrow tasks | Broader understanding and more reliable insights |
Training Data | Requires large, task-specific datasets | Uses datasets aligned with a single input type | Relies on large datasets covering varied inputs |
Challenges | Balancing quality, cost, and ethics | Limited scope, weaker context awareness | Integration complexity and high compute needs |
Examples | GPT-4, DALL·E, Stable Diffusion | BERT (text), ResNet (images) | CLIP, GPT-4o, Perceiver IO |
Comparing these approaches, it becomes clear that multimodal AI models extend the boundaries of traditional systems, offering adaptability and depth that unimodal or generative models alone cannot achieve.
10 Leading Multimodal AI Models in 2026
Research in multimodal AI models is moving quickly, with new systems designed to handle complex tasks across industries. These frameworks integrate different data types, demonstrating how the technology is maturing to solve real-world challenges.
CLIP
Contrastive Language-Image Pre-training (CLIP) is one of OpenAI’s most recognized contributions to multimodal AI models. This vision-language system links text descriptions with images, enabling it to perform image classification, captioning, and other cross-domain tasks.
Key Features
- Contrastive Learning Approach: CLIP applies a contrastive loss function to align images with relevant text. Minimizing distance between paired samples, the model learns which words best describe each visual.
- Text and Image Encoders: Its design combines a transformer-based text encoder with a Vision Transformer (ViT), giving it the power to process natural language and visuals in parallel.
- Zero-Shot Performance: Once trained, CLIP can extend to new datasets without specific fine-tuning, a breakthrough that shows how multimodal AI illustration works in practice.
Use Case
CLIP’s adaptability makes it valuable in many business settings. It can generate captions for digital media, support image annotation when building training datasets, and drive smarter image retrieval in search applications. Companies use it to create richer customer experiences, where text queries connect seamlessly with visual results.
DALL-E
DALL-E is OpenAI’s multimodal AI model that generates images directly from text prompts. Built on concepts similar to GPT-3, it is known for combining unrelated ideas, such as animals, objects, or even text, to create entirely new and imaginative visuals.
Key Features
- CLIP-Guided Architecture: DALL-E relies on the CLIP model to connect text inputs with matching visual semantics. This design allows the model to encode prompts into meaningful visual representations.
- Diffusion-Based Decoder: The image generator applies a diffusion process, gradually shaping realistic images from random noise conditioned on the text description.
- Extended Context Capacity: With 12 billion parameters and support for sequences of up to 1,280 tokens, DALL-E can create brand-new images or modify existing ones with remarkable precision.
Use Case
DALL-E shows how multimodal used in generative AI. It supports tasks like generating abstract illustrations, designing marketing visuals, or reimagining existing photos. Companies can use it to visualize new product concepts, while educators can rely on it to make complex ideas easier to grasp through images.
LLaVA
Large Language and Vision Assistant (LLaVA) is an open-source multimodal AI model that merges Vicuna with CLIP to process queries that contain both text and images. It delivers strong results in conversational tasks, achieving 92.53% accuracy on the Science QA benchmark.
Key Features
- Instruction-Following Dataset: LLaVA is trained on multimodal instruction data generated from ChatGPT and GPT-4. This data includes visual questions with conversational responses, detailed descriptions, and reasoning tasks.
- Language Decoder Integration: By connecting Vicuna as the language decoder with CLIP, the system fine-tunes effectively for visual-language conversations.
- Projection Layer: A trainable projection matrix allows LLaVA to align visual features with the text embedding space, improving coherence across inputs.
Use Case
LLaVA demonstrates practical multimodal AI meaning in building smart assistants. A retailer, for example, could deploy a chatbot where customers upload a product photo and instantly receive matches from the online catalog, making the shopping experience more interactive and efficient.
CogVLM
Cognitive Visual Language Model (CogVLM) is an open-source foundation system designed for vision-language integration. Using deep fusion methods, this multimodal AI model reaches state-of-the-art results across 17 benchmarks, including visual question answering and image captioning datasets.
Key Features
- Attention-Based Fusion: CogVLM incorporates a specialized visual module with attention layers to combine text and image embeddings. Freezing the LLM layers, it maintains high performance while learning visual-language alignment.
- ViT Encoder Backbone: The model employs EVA2-CLIP-E as its vision encoder, supported by a multi-layer perceptron (MLP) adapter that projects visual signals into the same representational space as language.
- Large Language Model Integration: CogVLM 17B connects with Vicuna 1.5-7B, allowing it to process text inputs and convert them into effective word embeddings for downstream tasks.
Use Case
CogVLM strengthens multimodal AI examples in real-world scenarios. It supports advanced VQA tasks, generates rich descriptions from images, and assists with visual grounding, where the system identifies objects in an image based on natural language queries. This makes it a strong tool for industries needing detailed vision-language interpretation.
Gen2
Gen2 is an advanced multimodal AI model built for video generation. It can transform text descriptions into moving visuals or convert still images into dynamic video sequences. Applying diffusion-based modeling, Gen2 produces context-aware results that align closely with both textual and visual prompts.
Key Features
- Latent-Space Encoder: Gen2 applies an autoencoder that compresses input video frames into a latent space, where they are diffused into compact vectors for processing.
- Depth and Content Recognition: The model leverages MiDaS for depth estimation of video frames and integrates CLIP to encode frame content effectively.
- Cross-Attention Mechanism: Through cross-modal attention, Gen2 fuses diffused vectors with structural and content features. A reverse diffusion process then reconstructs realistic, coherent video sequences.
Use Case
Gen2 reflects the progress of multi modal models in creative industries. Filmmakers and designers can generate short clips directly from text prompts, apply an image’s visual style to existing footage, or create entirely new video assets for marketing and entertainment campaigns.
ImageBind
ImageBind is Meta AI’s multimodal AI model designed to unify six different input types, text, audio, video, depth, thermal, and inertial measurement unit (IMU) signals, into one shared embedding space. With this setup, the system can accept data from any source and generate outputs across the supported modalities.
Key Features
- Flexible Output Mapping: ImageBind enables text-to-image, audio-to-image, image-to-audio, and cross-combinations like audio plus image-to-video creation.
- Image Binding Strategy: The model trains by pairing visuals with other modalities, such as aligning web videos with images or linking captions to corresponding pictures.
- InfoNCE Optimization: Using the InfoNCE loss function, ImageBind aligns non-visual data to images through contrastive learning, ensuring stronger cross-modal representations.
Use Cases
ImageBind highlights the scope of modality data in business and creative fields. A marketing team, for instance, can generate promotional visuals paired with tailored audio from a simple text prompt, delivering consistent multimedia campaigns with minimal manual effort.
Flamingo
Flamingo is DeepMind’s multimodal AI model built to handle video, image, and text inputs, then generate descriptive text responses. Its design supports few-shot learning, meaning users only need to provide a handful of examples for the model to deliver accurate and contextually relevant outputs.
Key Features
- Vision Encoders: Flamingo uses a frozen Normalizer-Free ResNet as its visual encoder, trained with a contrastive learning approach. It transforms pixels from images or videos into one-dimensional feature vectors.
- Perceiver Resampler: This module condenses high-dimensional visual information into a smaller set of tokens, reducing computational load while preserving essential details.
- Cross-Attention Layers: Embedding cross-attention layers inside a large language model, Flamingo fuses visual signals with text data to create richer outputs.
Use Case
Flamingo showcases how multimodal AI models apply to visual-language tasks. It can generate captions for images, support classification, and perform visual question answering (VQA), all framed as prediction tasks conditioned on the provided visual cues.
GPT-4o
GPT-4 Omni (GPT-4o) is OpenAI’s flagship multimodal AI model capable of processing and generating audio, video, text, and images in real time. Its design emphasizes interactivity, allowing it to respond with near-human speed and deliver outputs that feel natural across different channels.
Key Features
- Fast Response Speed: GPT-4o delivers replies in about 320 milliseconds on average, mirroring human conversational timing.
- Multilingual Capability: It can interpret and generate content in more than fifty languages, including French, Arabic, Chinese, Hindi, and Urdu.
- High-Level Performance: Benchmarked against GPT-turbo, GPT-4o excels in reasoning, text understanding, and coding, maintaining advanced results across domains.
Use Case
GPT-4o highlights what is multimodal AI in practice. It can generate expressive speech, produce images with detailed nuance, or combine text and video creation. This makes it an ideal tool for businesses aiming to create interactive marketing assets, customer engagement tools, or global communication systems.
Gemini
Google Gemini is Google’s family of multimodal AI models capable of processing text, images, video, and audio. Gemini is released in three main versions: Ultra for advanced reasoning and demanding tasks, Pro for large-scale enterprise applications, and Nano for lightweight, on-device use.
Key Features
- Expanded Context Window: Gemini 1.5 Pro can handle up to two million tokens, while 1.5 Flash supports one million. This allows the model to process lengthy videos, detailed documents, source code, and extended conversations.
- Transformer Training: The system is trained on interleaved sequences of audio, text, video, and images using a transformer backbone, enabling it to generate coherent outputs across channels.
- Post-Training Methods: Applying supervised fine-tuning and reinforcement learning with human feedback (RLHF), Gemini achieves more reliable and safer performance.
Use Case
Gemini demonstrates the power of multiple modalities in business and education. Developers can rely on Gemini Ultra for complex code generation, teachers may use Pro to review scanned student work, and companies can implement Nano for on-device assistants that respond instantly without depending on cloud processing.
Claude 3
Claude 3 is Anthropic’s multimodal AI model designed for both language and vision tasks. It comes in three versions, Haiku, Sonnet, and Opus, with Opus delivering state-of-the-art performance on reasoning benchmarks ranging from undergraduate to graduate levels.
Key Features
- Extended Recall: Claude 3 supports sequences exceeding one million tokens, giving it the ability to recall and analyze extremely long inputs.
- Advanced Visual Processing: The model interprets images, charts, graphs, and diagrams, handling research papers and technical documents in under three seconds.
- Improved Safety Protocols: Built with Anthropic’s alignment principles, Claude 3 handles potentially harmful prompts with greater subtlety while preserving accuracy.
Use Case
Claude 3 showcases how multimodal AI models are applied in education and research. It can parse dense academic texts, interpret complex diagrams, and provide structured explanations, making it a valuable assistant for students, researchers, and professionals dealing with technical data.
Top Industry Applications of Multimodal AI Models
Multimodal AI models are reshaping industries by combining diverse data streams to improve customer engagement, strengthen operations, and drive new innovation. Below is a closer look at how this technology is already delivering value across sectors.
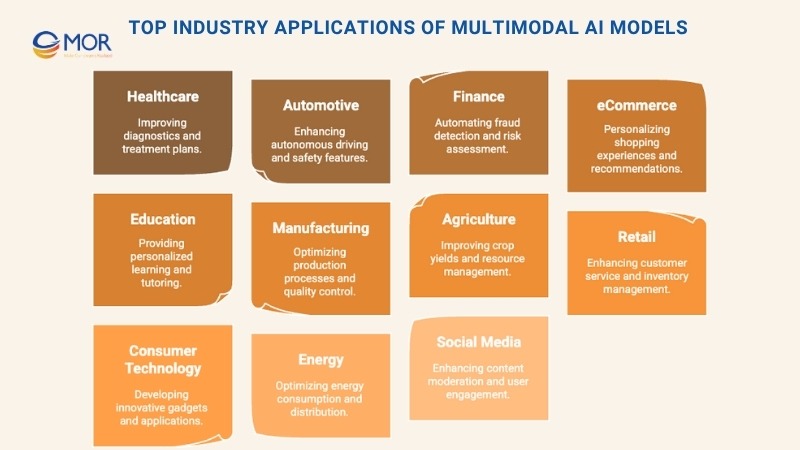
Healthcare
In healthcare, multimodal AI models merge information from electronic health records (EHRs), diagnostic imaging, and physician notes to support more accurate decision-making. This unified approach gives doctors a holistic view of a patient’s health, resulting in faster diagnoses and more personalized treatment strategies.
Analyzing these sources together, systems can identify correlations that single-modality tools might miss. That means better precision in detecting diseases, designing tailored therapies, and even predicting medical risks before they become severe. The outcome is proactive care, improved intervention timelines, and stronger patient outcomes.
Practical examples are already visible. IBM Watson Health combines EHRs, imaging data, and clinical notes to help clinicians diagnose conditions more accurately and forecast patient responses to treatments. Similarly, DiabeticU, a diabetes care app, integrates with wearables to track blood sugar, recommend diets, monitor exercise, and provide AI-driven guidance. This demonstrates how advanced multimodal models support ongoing health management in everyday life.
Automotive
The automotive sector is rapidly adopting multimodal AI models to strengthen vehicle safety and advance autonomous driving. Combining sensor data with inputs from cameras, radar, and lidar, these systems improve navigation, real-time decision-making, and overall vehicle performance. This integration enables cars to better recognize pedestrians, interpret traffic lights, and adapt to complex road conditions, which significantly boosts safety and reliability. It also powers advanced driver-assistance systems, including automatic braking and adaptive cruise control.
One of the most innovative multimodal AI examples comes from Toyota, which created a digital owner’s manual powered by large language models and multimodal generative AI. Instead of static pages, the manual now delivers an interactive experience that fuses text, images, and context-aware guidance.
This approach makes vehicle information easier to access and understand. With natural language queries, visual aids, and real-time updates, owners can quickly learn how to use advanced features. The result is a more personalized and engaging experience that highlights how multimodal AI models enhance both driving and ownership.
Finance
In financial services, multimodal AI models are being applied to improve fraud detection and strengthen risk management. Combining transaction records, user behavior patterns, and historical account data, these systems create a broader view of financial activity. This integration makes it easier to spot anomalies, detect fraud attempts earlier, and assess risks with greater accuracy.
A strong example is JP Morgan’s DocLLM, which demonstrates how these models enhance FinTech applications. DocLLM merges text, metadata, and contextual elements from complex financial documents to deliver faster and more precise analysis. The result is improved compliance processes, streamlined document handling, and better visibility into potential risks. This multimodal approach not only cuts down manual workloads but also equips financial institutions with sharper tools for decision-making.
eCommerce
In online retail, multimodal AI models are transforming how businesses engage with customers and manage operations. Analyzing user browsing behavior, product images, and written reviews together, these systems deliver more precise product recommendations, personalize marketing campaigns, and fine-tune inventory strategies. This integrated view improves product placement and creates smoother shopping journeys, ultimately raising customer satisfaction.
A notable case is Amazon’s use of these ml models to optimize packaging. Merging data on product dimensions, shipping requirements, and warehouse inventory, the system identifies the most efficient packaging option for each order. This not only reduces waste and material costs but also aligns with the company’s sustainability goals. The result is a smarter, eco-friendly eCommerce operation that benefits both customers and the business.
Education
The education sector is seeing major benefits from multimodal AI models, which merge data from text, video, audio, and interactive materials to enhance teaching and learning. Tailoring resources to individual preferences and skill levels, these systems support personalized learning paths that keep students more engaged. Multimedia-rich lessons improve knowledge retention and create a more dynamic classroom experience.
A strong example is Duolingo, which applies AI multimodal models in its language-learning platform. Through combining visuals, audio clips, and written exercises, the app adapts in real time to a learner’s progress and ability. This adaptive approach reinforces language skills, increases motivation, and ensures that lessons stay interactive and effective. Through multimodal integration, education providers can deliver richer and more impactful learning experiences.
Manufacturing
In the AI in manufacturing sector, multimodal AI models play a crucial role in improving efficiency and reliability. Combining data from equipment sensors, production line cameras, and quality reports, these systems support predictive maintenance, strengthen quality control, and streamline production workflows. The result is fewer breakdowns, higher productivity, and better end-product standards.
Bosch provides a strong example of this in action. Their factories apply models powered by multimodal AI that analyze sound patterns, sensor readings, and visual inspections together. This enables real-time monitoring of machine health, early detection of faults, and proactive maintenance scheduling. With this integration, Bosch reduces downtime, increases throughput, and consistently maintains high-quality production.
Agriculture
In farming, multimodal AI models are helping improve crop management and boost efficiency by bringing together satellite images, in-field sensor data, and weather forecasts. This unified analysis enables more accurate monitoring of plant health, smarter irrigation and nutrient planning, and timely responses to pests or disease. With these insights, farmers can allocate resources better and predict yields with greater precision.
John Deere is a leading example of this innovation. The company equips its machinery with multimodal AI systems that combine IoT data, machine learning, and computer vision. These systems support precision planting, track crop conditions in real time, and deliver insights that guide field operations. The outcome is higher productivity, reduced waste, and improved yields, showing how agriculture can be transformed through AI-driven decision-making.
Retail
In retail, multimodal AI models drive smarter operations by combining data from shelf cameras, RFID systems, and sales transactions. This integration strengthens inventory tracking, improves demand forecasting, and enables tailored promotions. The outcome is smoother supply chain management and shopping experiences that feel more personalized to each customer.
Walmart showcases this approach effectively. Applying multimodal AI frameworks to merge in-store shelf data, RFID readings, and purchase histories, the company refines stock management and anticipates demand more accurately. At the same time, it can design targeted promotions that match customer needs. This leads to higher operational efficiency while ensuring shoppers find the right products at the right time.
Consumer Technology
In consumer tech, multimodal AI models elevate voice assistants and smart devices by combining speech recognition, natural language processing, and visual input. This integration allows devices to deliver context-aware responses, making interactions more intuitive and engaging across a wide range of applications.
Google Assistant is a prime example. Blending voice recognition with NLP and visual data, it creates a smoother and more interactive user experience. Users can issue voice commands, receive personalized feedback, and access advanced features seamlessly across phones, tablets, and smart home devices. This shows how multimodal AI solutions are redefining daily digital interactions.
Energy
In the energy industry, multimodal AI models strengthen operations by merging data from geological surveys, environmental studies, and real-time sensor readings. This integration improves resource management, optimizes production workflows, and enhances overall efficiency. With access to these diverse data streams, energy companies can anticipate problems sooner, adjust strategies on the fly, and make better long-term decisions.
ExxonMobil demonstrates this application well. Combining operational sensor data with geological and environmental insights, the company uses multimodal AI technology to optimize drilling, predict equipment needs, and adapt quickly to shifting environmental conditions. This approach raises productivity while supporting sustainability goals, proving the value of multimodal integration in energy production.
Social Media
In social platforms, multimodal AI models analyze text, images, and video together to strengthen user engagement and improve content management. Connecting these data types, the systems can better detect trends, measure sentiment, and understand how users interact with content.
This integration makes recommendations more relevant, supports precise ad targeting, and helps platforms identify harmful or inappropriate material more effectively. The outcome is a more personalized, engaging, and safer experience for users, while also improving overall platform performance and reliability.
Key Business Advantages of Multimodal AI Models
Adopting multimodal AI models gives businesses stronger performance, higher accuracy, and greater adaptability across industries. These systems create more valuable insights by drawing from varied data types, helping organizations address challenges with smarter, more reliable solutions.
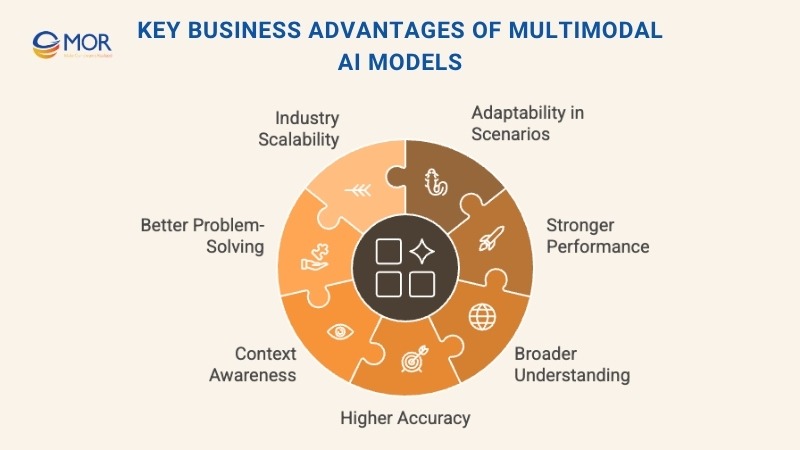
Adaptability in Practical Scenarios
When data from different channels is combined, multimodal AI models can address a wider range of business cases. This adaptability makes them effective in real-world environments where conditions and requirements vary greatly.
Stronger Overall Performance
Blending multiple inputs allows AI diversity systems to manage complex challenges more effectively. As a result, businesses benefit from more consistent, flexible, and dependable solutions powered by multimodal AI models.
Deeper and Broader Understanding
Merging insights from different inputs, multimodal AI models provide a fuller and more detailed perspective on the problem being solved. This integration gives businesses a clearer picture and better decision-making power.
Higher Accuracy
Compared to single-input systems, multimodal AI models reduce errors by analyzing varied data types such as text, visuals, and audio together. This combination produces more reliable and precise interpretations. In healthcare studies, multimodal systems usually come out on top. A 2025 survey of clinical tasks showed they beat single-input models in most direct comparisons, with clear improvements in average AUC scores.
Improved Context Awareness
With access to multiple data sources, these systems can interpret complex questions more effectively. Multimodal AI models generate responses that are contextually relevant and aligned with real-world situations.
Better Complex Problem-Solving
Synthesizing information from diverse sources, multimodal AI models enable businesses to tackle complex challenges with smarter and more innovative solutions. This capability makes them especially valuable in scenarios that require detailed analysis and creative problem-solving.
Ability to Scale Across Industries
The adaptable nature of multimodal AI models allows them to extend across multiple industries and AI marketing use cases. Their scalability supports business growth and makes it easier to adjust as new requirements or opportunities arise.
McKinsey projects that generative AI could contribute between $2.6 trillion and $4.4 trillion to the global economy every year. That potential becomes even greater when companies start applying multimodal inputs in real business operations.
Trends in Multimodal AI Models
Multimodal AI models are advancing quickly, with new directions shaping both research and business adoption. Several key trends stand out in 2026:
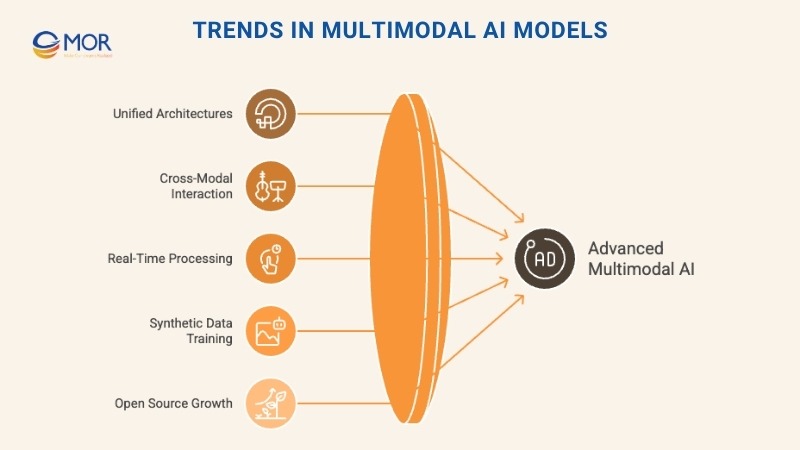
Unified Architectures
Models such as OpenAI’s GPT-4o and Google’s Gemini are being built to process text, images, video, and audio within a single system. These unified designs make it possible to generate and understand multimodal content smoothly without relying on separate pipelines.
Stronger Cross-Modal Interaction
Improved transformer structures and attention mechanisms are now aligning diverse inputs more effectively. This creates outputs that are contextually accurate and coherent, showing how multimodal AI models are becoming more precise and reliable across industries.
Real-Time Processing
Many industries now need multimodal AI models to analyze diverse inputs instantly. In areas like autonomous driving and augmented reality, systems merge data from cameras, lidar, and other sensors in real time to make split-second decisions that ensure safety and performance.
Synthetic Data For Training
To strengthen outcomes, researchers are creating artificial datasets that pair text with images, audio with video, or other combinations. This multimodal data augmentation expands training pools, making multimodal AI models more accurate and adaptable.
Open Source Growth
Platforms such as Hugging Face and Google AI are driving collaboration by releasing open-source tools. This shared ecosystem enables developers and researchers to improve multimodal AI models faster while encouraging innovation across the community.
>>> Let's explore the real AI development cost and make smarter budget decisions.
Risks That Come With Multimodal AI Models
Like other generative systems, multimodal AI models carry risks tied to bias, privacy, and evolving regulation. McKinsey advises organizations to adopt structured plans to deploy AI quickly but safely, ensuring guardrails are in place from the start.
One of the most common concerns is hallucination. With multimodal AI models, mistakes in one data type can cascade across modalities, compounding errors in the final output. This makes the consequences more severe than in unimodal systems.
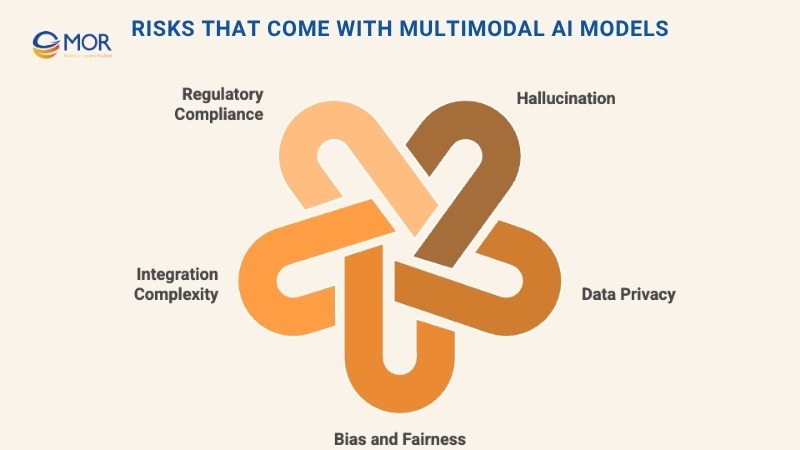
Other key risks include:
- Data privacy and security: These systems often process sensitive information across text, images, voice, or behavior patterns. Combining them raises privacy risks, particularly in areas like surveillance.
- Bias and fairness: Training data across multiple sources can contain deep-rooted biases. Without careful controls, multimodal AI models may reinforce or amplify them.
- Integration complexity: Designing architectures that accurately process and align varied data types is technically challenging, increasing the chance of misinterpretation.
- Regulatory compliance: Laws around AI and data use are changing rapidly. Intellectual property concerns are especially pressing when visual data or copyrighted material is involved.
How Can Organizations Mitigate These Risks of Multimodal AI Models
To manage the risks tied to multimodal AI models, companies should establish clear safeguards and adopt responsible practices. Leaders can apply strategies such as:
- Select models that are current, reliable, and suited to the specific task.
- Keep human oversight in place, especially for sensitive or high-stakes outputs.
- Apply these systems in scenarios where occasional inaccuracies are acceptable or where results can be quickly verified, such as software development in controlled settings.
- Build guardrails across the system to protect both end users and the models themselves, ensuring safer and more predictable outcomes.
How MOR Software Helps Organizations Harness Multimodal AI Models
MOR Software is not only a trusted software outsourcing company in Vietnam but also a technology innovator with a proven track record of helping enterprises adopt emerging technologies. With more than 850 global projects delivered across industries such as healthcare, finance, education, and retail, we understand how to translate complex AI research into practical business applications.
When it comes to multimodal AI models, our role goes beyond technical execution. We help organizations evaluate the right use cases, build custom strategies, and deliver scalable solutions that combine text, images, audio, video, and structured data. Our offshore AI developers are experienced in integrating AI with mobile and web platforms, enterprise systems, and cloud services to ensure performance, security, and long-term maintainability.
What we provide:
- AI Consulting services & Integration: Practical guidance on applying multimodal AI models in industries like healthcare (diagnostics and patient care), finance (fraud detection and risk analysis), and eCommerce (personalized recommendations).
- Custom Development Services: Building mobile apps, web platforms, and enterprise solutions that use multimodal AI for smarter interaction and decision-making.
- Agile Offshore Teams: Certified teams in Vietnam and Japan deliver cost-effective, high-quality solutions, following ISO 9001:2015 and ISO 27001:2013 standards.
- Sustainable Partnerships: We work with clients from concept to scaling, helping them continuously improve and adapt AI solutions as business needs evolve.
Combining global delivery capability with deep technical expertise, MOR Software is ready to help businesses turn the potential of multimodal AI models into measurable results.
Conclusion
Multimodal AI models are no longer experimental, they are shaping industries with smarter insights, higher accuracy, and more natural user experiences. From healthcare to finance, retail to manufacturing, their applications are vast and growing. Organizations that act now will be better positioned to compete in 2026 and beyond. Ready to explore how multimodal AI can transform your business?
Contact MOR Software today to discuss solutions tailored to your goals.
MOR SOFTWARE
Frequently Asked Questions (FAQs)
What are multimodal AI models?
Multimodal AI models are machine learning systems that combine and process different types of data, such as text, images, audio, and video, to deliver deeper insights and context-aware results.
What is an example of a multimodal model?
A common example is sentiment analysis that uses both the text of a tweet and any images included. This approach increases accuracy compared to using text alone.
Is ChatGPT a multimodal AI?
Yes. OpenAI has made ChatGPT multimodal, meaning it can analyze images, generate text, and even interact through speech on its mobile app.
Which LLM models are multimodal?
Llama 4 is one of the latest large language models with native multimodality. It uses early fusion to integrate both text and visual tokens into a single model backbone.
What is the difference between multimodal AI and LLM?
While LLMs focus on understanding text, multimodal AI goes further by analyzing multiple data types, including visual and auditory information, for richer context.
What is the difference between generative AI and multimodal AI?
Generative AI typically learns from one type of data, like text or images, to create new outputs. Multimodal AI requires more diverse data sources and integrates them to learn across modalities.
What are the limitations of multimodal AI?
Current multimodal AI models struggle with aligning data from different sources, require high computational power, and sometimes face difficulties generalizing in real-world use cases.
What is the future of multimodal AI?
The future points to broader use across industries like healthcare, autonomous driving, social media, and conversational AI. These models will continue to shape the next wave of AI innovation.
What is the main advantage of multimodal AI?
Its biggest strength is contextual understanding. By blending data types, multimodal AI systems can interpret complex situations more accurately and provide better interactions.
What is the main challenge when building multimodal AI?
The hardest parts are integrating different types of data, managing the computing demands, and ensuring stable performance across all modalities.
What is the opposite of multimodal AI?
Unimodal AI, or monomodal AI, is the opposite. It specializes in analyzing only one type of input, like text-only or image-only processing.
How is multimodal AI different from other AI?
Compared to single-modality AI, multimodal systems can generate more comprehensive insights since they capture relationships across text, visuals, sound, and other signals.
Why do we need multimodal models?
Multimodal models make AI more capable by using varied sources like text, images, and audio to understand the world better. This broader perspective allows AI to perform a wider range of tasks with higher accuracy.
What is the rise of multimodal AI models?
The rise of multimodal AI marks a key step in the evolution of generative AI. These systems can accept input across formats and deliver real-time responses with richer content.
What data types can multimodal AI process?
They can process and integrate text, images, video, audio, gestures, facial expressions, and even physiological signals. This diversity makes them highly adaptable for many industries.
Which industries can benefit most from multimodal AI models?
Healthcare, finance, eCommerce, education, manufacturing, and retail are leading adopters, using multimodal AI for better diagnostics, fraud prevention, personalization, and automation.
Share





Rate this article
0
over 5.0 based on 0 reviews
Your rating on this news:
Name
*Email
*Write your comment
*Send your comment
1